

文 | 柯鸣
来源 | 智能相对论(aixdlun)
八卦,似乎一直是人类茶余饭后的一个永恒的话题,怎么辨别一个人与另一个人的关系?比如是好朋友还是好基友?

但是,这一切私密的问题,AI已经能够做到精确识别了,这也着实引起了一波恐慌。就在此前,斯坦福大学两名研究人员开发了一个神经网络,可以通过研究一个面部图像来检测一个人的性取向。
研究人员训练了超过35,000张面部图像的神经网络,在同性恋和异性恋之间平均分配。该算法的追踪涉及了遗传或激素相关的特征。
这项研究的关键在于影响性取向的产前激素理论(PHT)。这个理论具体讲的是,在子宫中,对性分化负责的主要是雄性激素,也是以后生活中同性恋取向的主要驱动力。研究还指出,这些特定的雄性激素会在一定程度上影响面部的关键特征,这意味着某些面部特征可能与性取向有关。
研究发现,男女同性恋倾向于具有“非典型性别特征”,也就是说男同性恋通常趋向于女性化,而女同性恋反之亦然。此外,研究人员发现男同性恋通常拥有比直男更窄的下巴、更长的鼻子以及更大的前额,而女同性恋会拥有更大的下巴和更小的前额。

图片来源:TechCrunch
随机选择一对图像,一名同性恋男子和一名异性恋男子,机器挑选受试者的性取向准确率高达80%。而当与同一人的五张图像同时呈现对比时,精确度高达91%。不过,对于女性而言,预测准确率相对较低,一幅图像准确率为71%,有5幅图像,则上升至83%。
这一切都让人们感到了恐惧,AI识别人类性取向,无疑是涉及到了隐私部分,这确实是让人有所畏惧。而存储在社交网络和政府数据库中的数十亿公共数据将有可能在未获得本人许可的情况下被用来进行性取向识别,这也是有待商榷的。
除了识别性取向,还可以辨别人物关系
但是,这类型的研究还在继续。中山大学的一个团队可以通过数据集来识别人物关系。比如是这样:
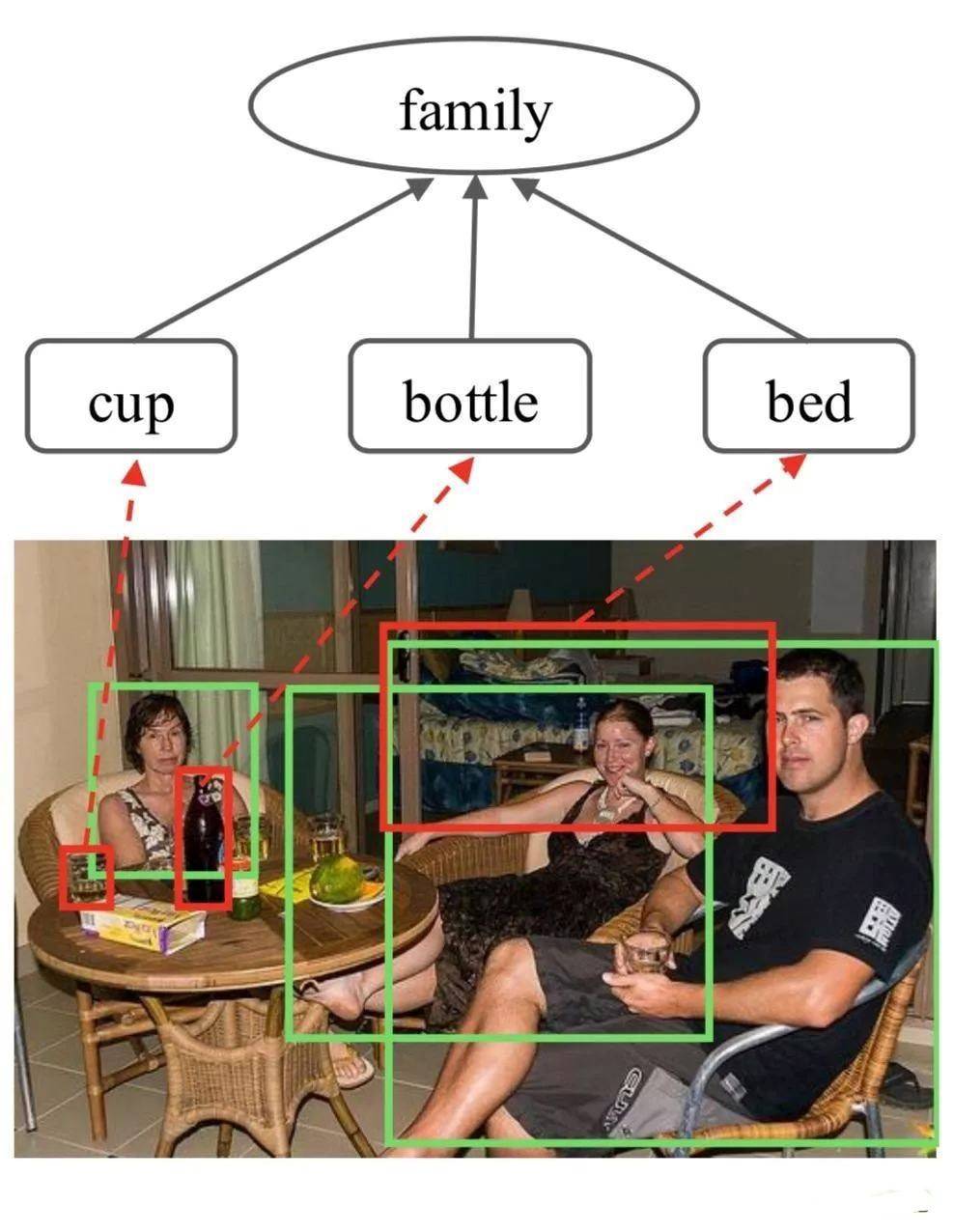
又或者是这样:
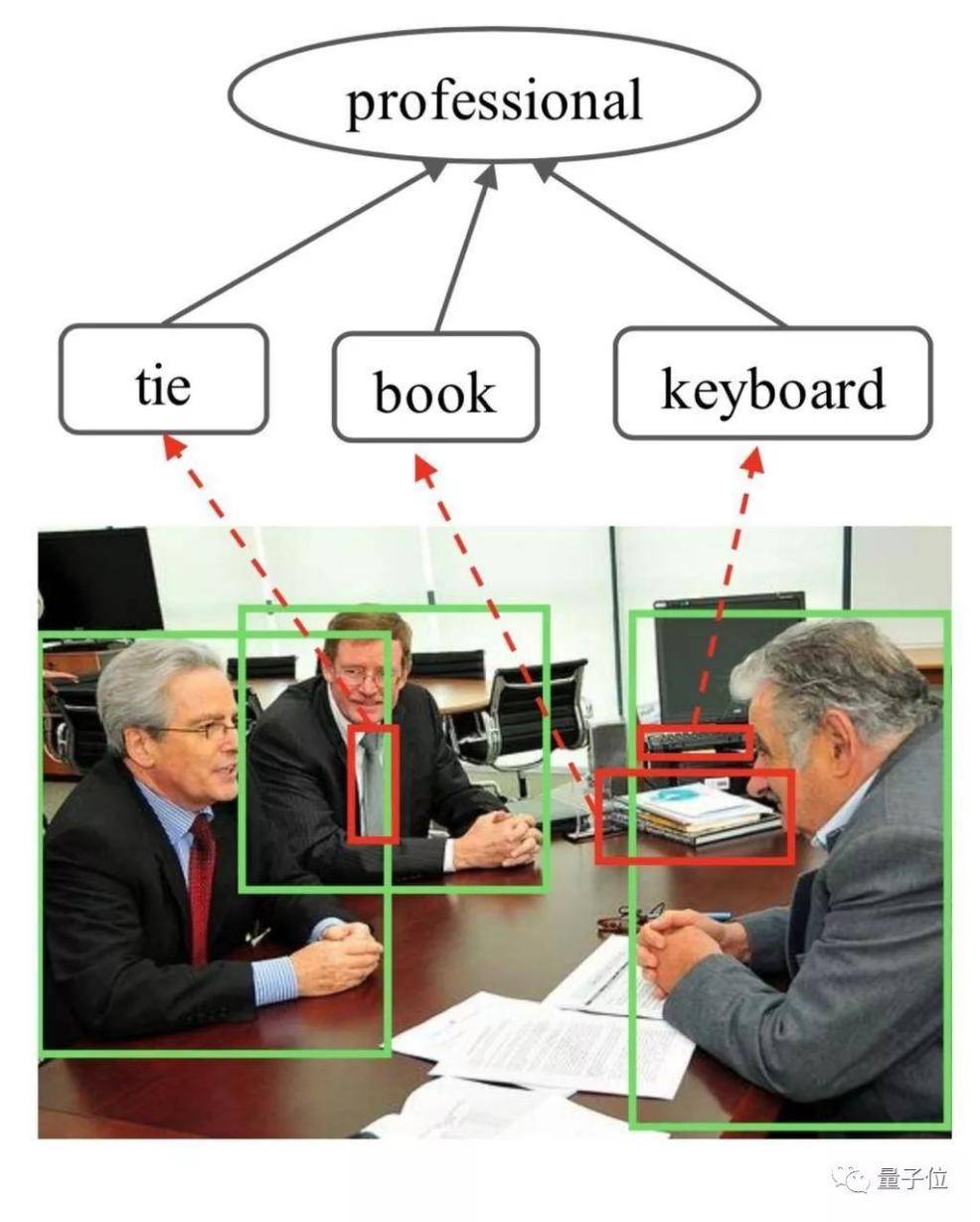
而这一切,基于研究者们训练了的图推理模型(Graph Reasoning Model,GRM),由该模型结合门控图神经网络(Gated Graph Neural Network,GGNN)对社会关系进行处理。
基于此,AI能够识别图片中三者之间的关系,根据图上人物区域的特征来初始化关系节点,然后用预先训练的Faster-RCNN探测器搜索图像中的语义对象,并提取其特征,初始化相应的对象节点;通过图传播节点消息以充分探索人与上下文对象的交互,并采用图注意机制自适应地选择信息量最大的节点,以通过测量每个对象节点的重要性来促进识别。
但是,在实际表现中,AI识别并未尽如人意。如警方在欧冠决赛采用AI面部识别匹配潜在犯罪图像,其错误率高达92%,而在人物关系和性取向识别领域,其应用表现也并不优秀。
性取向被识别后,AI伦理的边界又在哪里?
《纽约客》曾有这样一期封面:机器人已经成为了地球的主角,人类只能蹲在地上接受机器人的施舍。每一个新技术都会引发大家的担心,但以往更多是人的体力的延伸,而如若是脑力的延伸、人类隐私的延伸,这种担忧将会更加严重。智能相对论分析师柯鸣认为,性取向识别前,AI还需要解决伦理上的几大问题。
1.仅靠面部识别太草率
《人格与社会心理学》杂志曾对斯坦福的这个研究,指出深层神经网络比人类在通过图像检测性取向判断中更准确,研究涉及建立一种计算机模型,以识别研究人员将其称作为同性恋者的“非典型”特征。
在摘要中,研究人员写道,“我们认为人们的脸部特征包涵了更多人脑所无法判断的性取向特征。根据一张图片,系统(classifier)可以以81%的准确率区分男性同性恋者,74%的准确率区分女性同性恋者,这比人脑可以完成的判断准确率都要高。”
但是,在距离应用过程中,仅以面部构造识别似乎并没有那么“靠谱”。技术无法识别人们的性取向,所谓的技术未来只是识别出网络中同性恋者头像存在相似的某种模式。
而且,此研究存在的一个问题在于,研究的机制是通过两张图片二选一其中最让机器觉得“更可能是同性恋”的照片,这种对比判断其实是从 50% 的随机几率开始计算的,因此与单纯对一张图的分析有着很大的区别。
这其实就造成了一个问题,在真正人类识别的时候,其准确率有多少,而这种非此即彼的识别方式,其评判标准仍有许多地方需要商榷。
2.算法歧视依然是个“大问题”
算法歧视,一直是人工智能应用过程中的一大问题,以搜索为例,在谷歌上搜索“CEO”,搜索结果中没有一个是女性,也没有一个是亚洲人,这是一种潜在的偏见。
显然,人工智能也并不是真的纯“人工”。 机器学习的方式和人类学习一样,从文化中提取并吸收社会结构的常态,因此其也会再建、扩大并且延续我们人类为它们设下的道路,而这些道路,一直都将反映现存的社会常态。
而无论是根据面容来判断一个人是否诚实,或是判断他的性取向,这些算法都是基于社会原有生物本质主义(biological essentialism),这是一种深信人的性取向等本质是根植于人身体的理论。毕竟,一个AI工具通过数据积累和算法模型可以通过照片判断一个人的性取向,系统准确率高达91%,这其中所带来的性取向偏见是不能低估的。
今年年初,来自巴斯大学和普林斯顿大学的计算机科学家就曾用类似IAT(内隐联想测验)的联想类测试来检测算法的潜在倾向性,并发现即使算法也会对种族和性别带有偏见。甚至,连Google 翻译也难逃偏见,算法“发现”并“学习”了社会约定俗成的偏见。当在特定语言环境中,一些原本是中性的名词,如果上下文具有特定形容词(中性),它会将中性词转而翻译为“他”或“她”。
如今的人工智能还基本局限于完成指定任务,而有时候许多实际应用内容不是非此即彼的,在许多抉择中,人类选择依然存在道德困境,如若将决定权交与算法,其存在的诟病之处更是不言而喻。
3.数据使用,掌握“火候”是关键
如果说让AI野蛮生长是为了解决人们工作效率的问题,那么当人工智能逐渐落地于各行业后,“体面”已经逐渐取代效率,成为AI应用的关键词。
当然,如果企业能够全方位的保护用户隐私,这既有着技术上难度,也缺乏一定商业驱动力,因此,目前来看,如果平衡两者之间的关系才是关键。
实际上,在牵制巨头破坏用户隐私方面,欧洲国家已经走得很远,这体现在这些年他们与Facebook、Google等巨头对抗的一个个集体诉讼案例中:
2014年8月,Facebook在欧洲遭6万人起诉,一位奥地利隐私保护人士发起了一项针对Facebook欧洲子公司的大范围集体诉讼,指控Facebook违背了欧洲数据保护法律,FB被质疑参与了美国国家安全局的“棱镜”项目,收集公共互联网使用的个人数据。
今年1月初,德国政府一家数据保护机构周三表示,该机构已针对Facebook采取法律行动,指控Facebook非法读取并保存不使用该社交网站的用户的个人信息。德国汉堡数据保护办公室专员表示,由于Facebook在未经许可的情况下收集并保存不使用该社交网站的用户个人信息,这有可能导致Facebook被罚款数万欧元。
显然,目前用户对于自身数据的保护意识正在不断加强,其在不断保护自身数据的同时也加强隐私防范。毕竟,AI识别性取向目前只是研究而没有落地产品。
而且,从网站上扒图并不是什么技术活,让机器做选择题的概念,也像极了十多年前哈佛某个宅男做的校园选美网站。其中滋味,冷暖自知吧。
