

AI能说和听,这事儿大伙都知道。比如足够普及的智能音箱和手机里的语音助手、语音输入法。
而在感知智能这个大方向里,AI当然不只能说,同时还能看——比如说在张学友演唱会上抓个逃犯啥的。但AI的“看”不仅是识别人脸,同时也可以认识和判断物体。比如谷歌的猜画小程序就是依靠AI识物来实现的。
但这个领域,似乎还没有找到太多商业化的办法。人脸识别可以进行大规模安防应用,但AI识物在今天的更多应用展示,还是停留在游戏与炫技的层面。
有没有办法让AI识物的能力从“闹着玩”,变成“能赚钱”?
国内外各种AI势力正在努力破解这个问题。理想总归是美好的,而现实是缓慢掺杂着残酷。
AI之眼,似乎还没有给商业世界带来足够的魅惑。
Google Lens:下一个时代还是又一块鸡肋?
普通人能够应用的AI识物最主要还是集成在手机摄像头当中。当用户把摄像头对准想要识别的各种东西,AI系统就会通过图像识别以及OCR技术,给出相应的结果。
听起来还是蛮带感的。
目前这个领域探索幅度最大的则是AI巨头谷歌。在2017年I/O大会上,谷歌发布了集成在Google Photos里的Google Lens功能。通过这个功能,手机用户可以将摄像头对准各种各样的东西,然后让AI开口说话,告诉你ta看见了什么。

确切来说,Lens的很多功能还是相当实用的。比如当旅行者面对一个不知名的文物古迹,可以用Google Lens 来获知相关的历史以及文化知识;对准一瓶葡萄酒,AI可以告诉你这瓶酒的各种信息,比如年份、品饮方式、价格等等;在异国他乡拍摄交通指示牌,AI会借助谷歌翻译的力量把这些信息翻译出来。
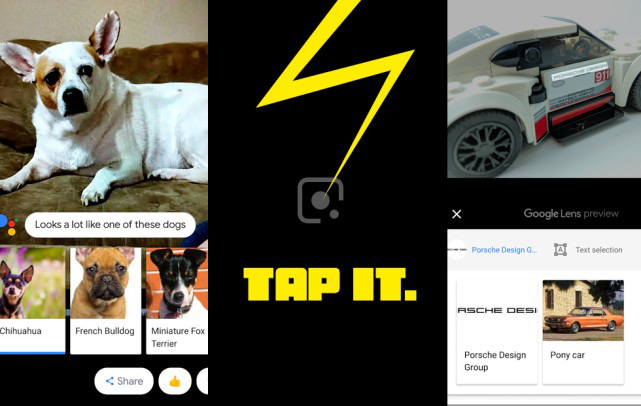
谷歌没有公布Lens到底能识别多少东西,但就目前情况来看,其可识别种类已经相当多。在今年的I/O大会上,该功能还被进一步升级,可以用来拍照识别文字信息、推荐穿搭风格,甚至还能识别海报给出的艺人资料与作品。
从一年的发展来看,谷歌对于Lens的期待很大,不仅升级了它的产品地位,还不断激发新功能,并建立与谷歌其它AI应用的联系。
虽然看似无所不能,但什么都能识别的Lens也有软肋:Lens的真实工作流程是将识别物体与数据库进行匹配。换言之数据库的大小直接影响着Lens的使用体验。而其技术本身的创造力则乏善可陈。比如吴恩达去年就无情嘲笑过:Lens的识花功能其实早就是百度玩剩下的。
目前来看,Lens在真实生活中还是“偶尔惊艳、日常痴呆”。当然对于中国消费者的不便就更多了,比如Lens目前并不支持中文。
但是AI识物这条路却是兵家必争之地,微软就不断宣称Bing搜索中的拍照搜索一点也不比Lens差。
可无论是谷歌还是微软,都无法解决AI识图搜索的根本问题:用户打开率低,商业化程度较差。
垂直行不行?国内的玩AI识物的几个场景
相比于谷歌非常强势地推出了“用我可以识别一切”的AI识物功能。国内AI企业,无论是BAT还是创业公司,似乎都还处在这一技术应用初级开垦阶段,同时也更聚焦于快速商业化的可能。集中表现就是,国内AI识物的应用大多集中在几个场景中:
1. 识图购物。这个功能已经屡见不鲜,无论是淘宝天猫还是京东,都已经投放了识图购物的功能。让用户可以通过拍照进行商品匹配,较高效率获知现实中商品在自家平台上的价格。就技术解决方案来说,由于拍摄商品往往是特征较明显、信息比较明确的AI识别品类,比如衣服、箱包等等,所以这类识图技术难度不高,加上完整的商品数据库,并不需要很强的技术探索能力。但缺点也很明显,那就是用户打开的针对性太强。
2. 识花。各种各样的识花软件和产品功能早已经洗礼了中国用户的AI常识。目前花卉植物的AI识别能力已经被做得相当精准。问题可能集中在这类应用大部分还是需要调用云端数据库进行匹配,识别速率并不高。而跟识图购物同样的问题,在于应用场景太狭窄。毕竟大家都没空天天春游……
3. 识字。相比于识别花卉,文字识别其实对于OCR纠错、模糊识别等领域的技术挑战更大。尤其是识别手写体以及古文字。而国内很多AI创业公司已经开始聚焦于拍照识别文字的细分应用领域。比如我们已经能看到AI识别和录入名片、用AI拍照并实现外文翻译以及旅行中用AI来识别碑刻、匾额、金石文字等等为旅游增添乐趣。
4. 批作业。从文字识别引申出国内另一个AI识物的主要流派,是用AI来识题和批改作业。这一领域要求足够的数据支撑和手写体识别能力,目前只能说还处在早期应用阶段。但对于数学等科目来说,AI批改作业和判试卷已经基本能够实现。而且批作业的AI还引申出另一个应用——用AI来答题的考试作弊神器。
这四大领域当然各有市场可能性,但同样的问题在于用户可能不会花费大量时间沉浸在某个细分识别领域。毕竟拿起手机来拍摄物体,很难变成一个随时发生的使用习惯。
要全能还是要专精,AI识物到底应该是一门怎样的生意呢?
想象力与困难并存的AI视觉应用
从谷歌的产品逻辑中,我们能够发现,AI识物的出现是希望用户能够面对生活中各种东西:无论是猫狗、花草、海报信息还是街道建筑,都拿出手机拍一下,让AI告诉你这背后的答案。
这个让AI告诉我们一切的方案,出发点当然是好的。但问题在于这违背了大部分用户的搜索引擎习惯,而且我们生活中遇到的绝大多数问题,都不是货真价实摆在眼前的物体,而是某个知识、信息或者答案。这些东西都是无法用拍照来搜索的,甚至信息的搜索强度远远大于对眼前真实物体的不知所措。
另一方面,AI识物的准确度还有待提高,一两次发现AI识别错误或者恶意卖萌之后,用户自然就很难再形成尝试冲动。
所以万能的AI识别一切,似乎并不是这门生意的真正面目。
场景化的使用中,主要问题在于出现频次不高,很难培养用户的使用习惯,当然也就很难沉淀到商业化的层级当中。目前来看,这个问题的解决方案很可能在于将AI识物的技术与某些相对高频发生的移动互联网需求相联系,在营销的帮助下形成场景化习惯。
最有可能的当然是旅游。我们能够发现,无论是识别花草,识别碑额,还是识别名胜古迹、翻译交通指示牌和菜单,这些都是旅行中的某个因素。而识花用识花的APP,翻译用翻译机,识别古迹再调出专门的小程序,这种体验恐怕大部分人会觉得很烦。
因此来看,在旅行场景的统一规划下,整合各种AI识物应用,形成一站式旅行AI,似乎在今天比较有机会。而BAT和旅行APP由于坐拥技术和数据优势,似乎更有可能成为这个领域AI应用的整合者。当然,能借助机器视觉能力诞生新的AI巨头,是我们更加希望看到的。

与旅行类似,AI识物的另一个机会在于儿童市场和教育市场。儿童需要用AI来识别和感知的东西更多,而让AI来给好奇宝宝提供关于生活中各种事物的解答,似乎也比较能够被年轻父母所接受。而更重要的识别类应用在于教育,无论是老师批作业,家长辅导孩子,甚至于学生寻找答案,毫无疑问都是很痛苦的过程。能够用AI来整合和激活这个市场,那么前景应该是相对客观的。
AI语音的理想状态是通过对话来控制生活中的一切,包括智能家居硬件、内容、手机与购物。AI识物的理想商业状态也是能够形成超级平台,让我们在面对生活中所有不解和好奇时,都拿出手机来拍一下,让AI告诉我们答案。
但世界搜索的需求限制以及技术目前本身的瓶颈,确实在降低这种超级平台的诞生可能性。但在垂直场景中,毫无疑问AI识图是能够提升人机交互效率,并且非常酷炫有型的搜索方式,商业市场也依旧是足够充沛的。
此外,目前也有若干问题在限制这一技术的应用度。比如上文说过的模糊识别精度不高问题,经常会造成用户的需求与AI答案之间南辕北辙;再比如中文知识图谱体系不够完整,很多领域我们目前还没有足够AI回答的中文数据;还有一个问题,是很多AI识物的场景,其实是对摄像头的反应能力有要求的,这就放弃了很多低端机入门机搭载AI识别应用的可能性。
让AI帮我们看世界已经足够近,却又比较远。远近之间的故事,可能才是需要无数科技公司想破了脑袋去参悟的。
