

“为什么这个图像识别的人工智能(AI),老把男人认成女人?”
赵洁玉发现这个问题的时候,正摩拳擦掌地准备开始自己第一个独立研究。那时,她刚加入弗吉尼亚大学计算机系攻读人工智能机器学习方向的博士,她的导师文森特•奥都涅茨(Vicente Ordóñez)扔给了她这个乍看有点哭笑不得的课题。

面部识别已经不是稀罕事了 | MIT Media Lab
这年头,面部识别其实已经不是很难的事情了,分辨男女更算不上什么世纪难题,准确率应该很高才对。当然,赵洁玉手头的AI任务要稍微难一点儿,不是分辨证件照,而是要辨认场景复杂的生活照。可就连相机里的小小程序都能极为准确地找到画面中的人脸而自动对焦,多点儿背景对AI来说能算什么难题呢?
然而正是这些背景,以一种意料之外情理之中的方式扭曲了AI的“认知”。赵洁玉发现,男人被认成女人的图片有一些共同点——都是站在厨房里,或者在做家务。
她很快意识到,这并不是程序bug,也不是识别算法或者特征提取出了毛病,而是人工智能总把女人和某些特定的元素联系在一起,在下达判断时被这些元素带跑了。换句话说,这是一个会“性别歧视”的AI:它认为站在厨房里的就“该”是女人。
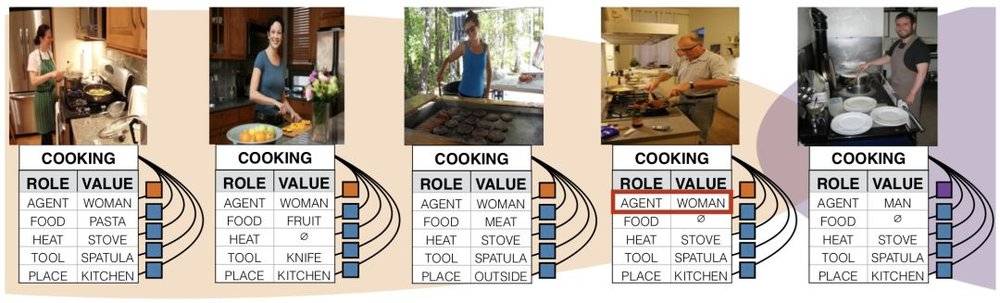
把男人认成女人的 AI | 参考文献1
这样的歧视是怎么产生的呢?也很简单。如果你成长在一个“男主外、女主内”的社会,那么你便会天然地认为女人就该操持家务。AI也一样,不过它“认识世界”的途径也是歧视的来源,是它的“教学资料”——用于训练人工智能进行图像识别的数据库。关于性别的偏见不仅在数据库里普遍存在,而且还会被人工智能所放大。
为什么会出现这种情况?怎么解决?赵洁玉和团队围绕着这两个问题写就的论文《男人也爱购物:使用语料库级别的限制法降低性别偏差》在自然语言处理2017年的年会上获得了最佳长论文奖,整个人工智能领域也开始逐渐意识到这个问题。
数据库的偏差从何而来?
赵洁玉和实验室团队选取了两个具有代表性的图像训练数据集,一个是华盛顿大学开发的ImSitu,一个是微软和Facebook等大公司支持的MSCOCO,每个数据集里面都有超过10万张图片。他们发现,一些标签和性别绑定的程度十分突出,比如站在厨房里、做家务、照看小孩子的就被认为是女性,开会、办公、从事体育运动的则是男性。单个图片看起来都很正常,然而大量的此类照片累积成了肉眼可见的偏见。有超过45%的动词和37%的名词,会展现超过2:1的性别比例偏差。
性别歧视也仅仅只是偏见其中的一个方面。一张来自印度海得拉巴的印式婚纱,在图像识别的人工智能眼里,成了欧洲中世纪的锁子甲。为什么?因为AI的概念里婚纱是白色的西式婚纱,而并不“认识”第三世界的文化。

左边为海得拉巴婚纱,右边为锁子甲 | Pinterest
这是谷歌大脑实验室成员、斯坦福大学的史蕾雅•珊卡尔(Shreya Shankar)的研究对象——目前最知名的图像识别训练数据集,拥有超过120万张图片的谷歌ImageNet。她发现,用ImageNet训练出来的人工智能,同样是识别带有“婚纱”元素的图像,来自美国和澳大利亚的图像准确率和置信度非常高——绝大多数图片都能得到机器自信且正确的答案;然而来自巴基斯坦和埃塞俄比亚的图片则没有这种待遇。在识别美国和第三世界的图像内容的时候,人工智能总是“选择性失明”。
珊卡尔用地点标签为这些数据做了分类,发现ImageNet的图像,有45%来自美国,超过60%来自最主要的6个欧美国家。而中国和印度加起来有全球三分之一的人口,却只有数据集里区区3%的数据量。在这样的数据集训练下的AI,在面对来自“第三世界”的任务时,就仿佛进了大观园的刘姥姥,眼前全是稀奇事儿。
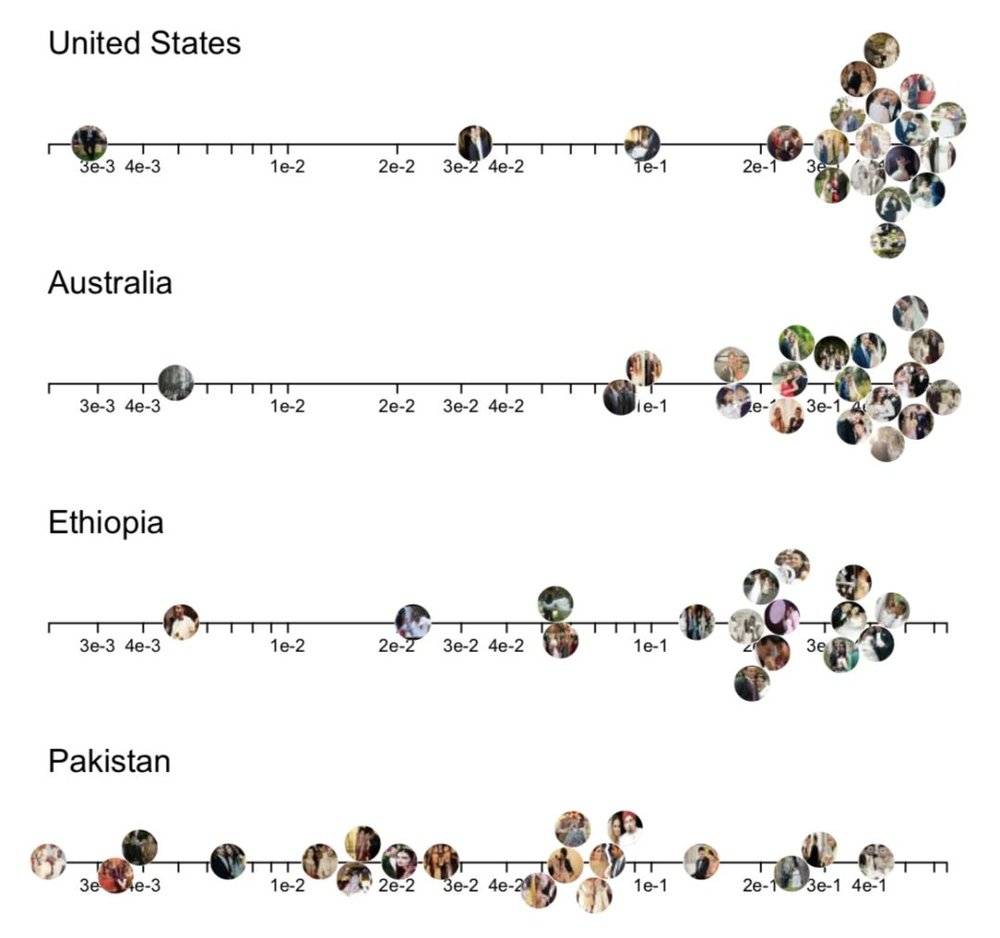
对于各地区的图像识别置信度的分布,越往右越高。埃塞尔比亚和巴基斯坦的图片置信度相对更差 | 参考文献2
数据集的偏差,在形成的过程中就已经在积累了。
数据集的目的,是训练机器进行图像识别——例如ImageNet 的图像就围绕着1000多个类别展开,每一张图片都有一个类别标签。但是为每个标签选择的图像,却会在无意中反映互联网的刻板印象。赵洁玉告诉我,大部分数据库的图片都来源于搜索引擎,然后再通过人工给这些图片加上标签,标注里面都有什么(比如一个香蕉的图片,那么标签里面就会有水果、食物、香蕉等文字)。这样做的原因很好理解:程序无法直接感知到现实事物,只能“看”到现成的数字化图像,而互联网搜索引擎应该是最不带偏见、最诚实的图像来源了吧?

人工给数据库的图片打上标签 | Pixabay
但搜索引擎体现的“诚实”却让人惊愕——比如,在谷歌上搜“black girl”,第一屏有绝大部分都是色情图(后来谷歌把这个问题修复了);哈佛大学的计算机系教授拉谭雅•斯威尼(Latanya Sweeney)发现,在搜索引擎上搜典型的黑人名字,搜索引擎会有超过80%的概率在搜索建议里提供“逮捕”、“犯罪”等词汇,而没有种族特征的却只有不到30%。归根结底,搜索引擎反应的并不是现实,而是它的使用者对现实的理解。这些关于种族与性别的理解不可避免地天生就有值得商榷的内容——你以为你输入的是“黑人”,但得出的内容却是“黑人罪犯”。
“数学上没有所谓‘公平’的概念,”英国巴斯大学计算机系教授乔安娜•布莱森(Joanna Bryson)说,“偏见,只是机器从数据中拾取的规律(regularity)而已。”在人工智能和机器学习的范畴里,“偏见”并不是一个带有价值判断的词汇。然而,在涉及到现实应用的领域,情况就不一样了。现在的机器,当然不具备体会情感或者故意施加偏见的能力,只是诚实地反映了数据库乃至社会中真实存在的偏见,而这些反映有时候并不是我们想要的。

搜索引擎诚实地反映偏见 | Pixabay
更关键的问题在于,现有的机器训练方式,很可能会放大这些偏见和歧视。
机器如何放大数据库的偏见?
你可能有这样的经历:刚在购物网站上购买了5kg的洗衣液,推荐算法就在“你可能喜欢”的侧栏里,给你推荐8个品牌25种其它洗衣液——“这是要我开洗衣店”?
大规模商业应用的推荐算法不够“智能”也许有其苦衷,但哪怕学术界顶尖的技术也难逃类似的坑:算法似乎太过在意你的输入,把原始数据太当真了。如果数据质量很高,那自然不是问题;但现在原始数据里已经有了偏见,算法就会进一步把它放大。
赵洁玉团队用MSCOCO和ImSitu数据集训练的人工智能,在对一般的图片进行预测的时候,会体现出比数据集本身更大的偏差——比如,在imSitu数据集中,“下厨”和女性联系起来的频率为66%,男性有33%;然而,被这个数据集训练过的人工智能,预测下厨和女性联系起来的比率被放大到了84%,男性则只有区区16%。

AI会将下厨和女性的联系放大 | Pixabay
为什么呢?她在研究中使用的算法模型,一方面直接通过辨认图像的特征,提取图像里的元素标签,另一方面会根据各个标签之间的联系来判定究竟哪个元素出现的概率最大,这也是大信息量的图像识别中十分常用的思路。而问题就在于,如果要通过现有的联系来进行识别,那么机器可能会在训练中将现有的联系夸大,从而在不那么确定的情况下,给出一个更可能靠近“正确答案”的结果。
赵洁玉给我打了个比方:“当算法只通过图像里的特征来判定,给出的预测是有50%的可能图片里面是男性,但也有50%可能是女性;但在训练它的数据库中,有90%的图片都将女性和厨房联系在一起。那么综合图像特征、联系两方面信息之后,机器便会得出结论,说图片里是女性。”
AI会将现有的联系夸大丨Pixabay
机器容易犯的另外一个错是将大部分数据的特征当做一般的特征来处理——上文中用ImageNet训练出来的数据库就很可能犯“美国加欧洲就是全世界”的错误。这会对数据中的少数非常不利。如果让AI判断一个人是男人还是女人,而用于训练这个AI的数据库里有98%的男人,只有2%的女人。经过训练的AI即使可以识别所有男人、完全不管那2%的女人,那也能有98%的准确度。但是那2%的女人,对机器就等同于不存在了。
而如果不管不顾实际情况,只埋头训练的话,能将现有数据库的偏差夸张到什么程度呢?来自MIT和卡耐基梅隆大学的两个学者训练了一个AI,它能够通过不同数据库的风格和内容,识别来自不同数据库的图片,比如Caltech101里的汽车都是横着的,MSRC里常常是宽阔的草坪上摆着一个物体。这意味着,若一个数据库里面出现了哪怕一点点的偏见,也会被算法忠实地反映出来,夸大到一般情况中——用Caltech101训练出来的AI,一定认为世界上绝大部分的车都是横着的才“正常”。

不同数据库里的车的“典型”样子 | 参考文献3
这在技术领域被称为“过拟合”,很大程度上和人工智能的训练方式有关。MIT和卡耐基梅隆的研究者认为,现在的图像识别开发者,往往会陷入盲目追求“准确度”的陷阱里去。训练出来的模型,在某一个数据库上的精确度可以达到非常高,从而给人“我的AI特牛逼”的错觉,然而在现实中难免会吃瘪。这就好比我本来是个脸盲,又恰好是日本大型偶像组合AKB48的忠实粉丝,里面的几百个妹子我都认识;但是把我放到一般人群中,我又两眼一抹黑,只好对着刚认识不久的人露出陌生的微笑。长期泡在年轻妹子里,对老年人和男性的识别能力反而降低了。
诚然,在AI训练的过程中,数据可以说是最重要的一环。但数据不是万能的,对数据的洞察同样关键。“从大量的数据中挖掘并洞察人性”——这是赵洁玉的导师奥都涅茨的兴趣所在。只有这样,才能从根本上提高机器在人类社会中工作的能力。
人或许是机器最大的局限
社会的信息化、互联网的飞速发展给我们带来了海量的数据,你想得到的、想不到的,都被机器清清楚楚地掌握着。在你打开社交网站的时候,机器就把合适的广告推到了你面前,只因为你前一天用谷歌搜索了这个产品的信息;上传照片到Facebook,你和你的朋友都会被自动打上标签,只因为面部识别算法早已悄悄扫描过了有你们的每一幅照片。

互联网甚至已经能识别你的面孔 | Pixabay
然而,对于数据的挖掘和理解,始终有着各种各样的局限。机器的错误、歧视和偏见也来自“缺根筋”的人——技术人员拥有了大量的数据,用机器强大的运算能力调教出了精妙的算法,但却对数据、乃至数据背后的社会现实缺乏考虑。
珊卡尔举了一个让人啼笑皆非的例子——她所在的斯坦福计算机系的一个教授开发了一个声称能够“通过面部特征识别同性恋”的人工智能。消息传出,社会上一片哗然。且不论这个算法若是放入现实中,会为歧视和偏见提供怎样的方便;关键是这个人工智能在现实中真的成立吗?“这位教授使用的数据,都来自在调查里公开出柜的人,还有大量的同性恋根本没有公开自己的性向。”珊卡尔在一篇博文中写道,“如果想要辨识一个人是否真的是生物意义上的同性恋,这个算法没有任何意义。”
另一个例子是,一个医疗团队使用AI辅助诊断病人的血液样本(这可以说是目前人工智能最有开发潜力的方向之一),但却发现AI诊断出阳性结果的数量大大超出了预料。难道其实人人都有病?结果却令人啼笑皆非:数据库使用健康志愿者的血液作为对照,但这些志愿者几乎都是年轻的大学生,而医院里的病人年龄明显偏大。最后,人工智能把老年血当成了有病的血。这样的错误人类也会犯,但只需上几门医学统计学的课程就可纠正;教会AI懂得这种偏差,却仿佛遥遥无期。
如何教会AI分辨老年血和有病的血 | Pixabay
这还仅仅是学术领域的问题,现实中关于数据库的棘手事儿更多。“在机器学习研究的领域里,数据库还是相对比较‘干净’的,”一名在人工智能领域供职的朋友对我说,“各种类型的数据都比较理想化,比如图片的标签、图片的分类等等,都相对规范。然而在商业领域采集到的数据,很多都非常潦草,训练出来的算法也有很大问题。”商业公司要么购买昂贵的数据库,要么就花上大量的人力手动打标签,从这个角度上讲,人工智能的背后,其实一点也不智能。“垃圾进,垃圾出”(Garbage in,Garbage out),是业界对于糟烂数据库训练出糟烂智能的吐槽——很多时候,甚至是自嘲。
这些进入商业应用的人工智能使用了什么样的数据库?数据库中的偏见是否会影响人工智能的判断?数据库如何收集数据,如何标注已有的偏见,业界有没有标准?社会对此缺乏相应的考察,而机器学习本身也存在着大量不透明的境况,特别是在神经网络“无监督学习”的发展趋势下,连开发者自己都不知道自己的 AI 究竟在干什么。
我们不知道一个进行简历筛选的智能,会不会将女性的简历扔进垃圾堆;也不知道给一个人的借贷信用打分的人工智能,是否会将出生地作为黑历史纳入考虑。作为一个希望在计算机领域发展的女性,赵洁玉也会担心这样的问题。“如果你用历年计算机系的入学数据训练一个人工智能,”她说,“那么机器一定会得出‘女性成不了优秀的计算机工程师’的结果,这对女工程师来说非常不公平。”

AI的偏见会不会导致现实的性别歧视 | Maxpixel
而少数族裔、少数团体所面临的尴尬,就如同珊卡尔的研究中的海得拉巴婚纱一样——被主流数据库训练出来的人工智能,对少数群体的情况往往两眼一抹黑。
现实中,大量的智能应用都诞生自湾区——这是一个经济极其发达的城市带,开发者大部分是白人中青年男性,而这个小小的地方,正决定着服务整个世界的人工智能的数据和算法。国内北上广深杭的互联网从业者,也难免对三四线城市和乡村充满了轻蔑,一厢情愿地相信着大城市的社会规律。而结果却是,那些没有话语权的群体和地域,可能会在将来更加严重地被边缘化,这并不是开放、平等的互联网最初所期冀的结果。
给机器一个公平的未来?
“没有事实上的技术中立。对机器来说,中立的就是占统治地位的。”剑桥大学未来研究所教授鲁恩•奈如普(Rune Nyrup)如是说。人工智能并不能从数据中习得什么是公平、什么是美德,也不懂什么是歧视、什么是丑恶。说到底,我们现在的人工智能,还远远没到理解“抽象”的地步。
被人类盲目追捧的机器,似乎不会“犯错”——这是因为机器是稳定的,只会出现“异常”。但这种异常,其实就是一直固执不停地犯错。如何避免呢?这也跟人类的教育有相似之处——提供更好的教材,或者老师需要格外注意教学方式。毫无疑问,我们需要更好的,尽可能减少偏见的数据库;然而得到面面俱到、没有偏差的数据库非常困难而且成本高昂。那么训练人工智能的技术人员,能够对可能的偏差有所认识,并用技术方式去调整、弥合这个偏差,也是十分必要的。

对机器的训练与人类的教育相似,需要好的教材或格外注意的老师 | Pixabay
赵洁玉正在做的研究,就是如何调偏。她设计的算法,会衡量数据库的性别元素和偏见状况,并用它来纠正识别的预测结果。在这个纠偏算法的帮助下,机器在性别方面的识别偏见减少了40%以上。
而在纠偏的研究中,赵洁玉也慢慢领会了一个技术人员与社会公平之间的联系。她自认并不是那类积极在社交网络上参与政治议题的年轻人,但却会更多地在技术领域注意到数据中的“少数”,思考他们是否得到了数据和算法的一视同仁。“你的算法表现好,是不是因为优势群体强大?弱势群体在你的算法中被考虑到了吗?”赵洁玉说。
而从根本上说,那些被机器无意拾取的偏见,都以性别刻板印象的形式,长期存在于我们周围,需要我们保持审视的态度。作为一个从事人工智能研究的女性,即使已经走入了领域最顶尖的学府深造,却依旧会面对别人诧异的目光。“经常会听到别人说,‘女孩子学CS(Computer Science,计算机科学),一定很辛苦吧’。”赵洁玉对我说。这些无心的、甚至是赞扬的话,却让自己听了觉得不对劲,“明明大家都是一样的啊。”

别忘了,第一位程序员也是女性(当然,电脑是艺术加工的) | MASHABLE COMPOSITE ALFRED EDWARD CHALON/SCIENCE & SOCIETY PICTURE LIBRARY
的确,我们需要不厌其烦告诉机器的或许也需要不厌其烦地告诉我们自己。
参考文献:
1.Zhao, Jieyu, et al. “Men also like shopping: Reducing gender bias amplification using corpus-level constraints.” arXiv preprint arXiv:1707.09457 (2017).
2.Shankar, Shreya, et al. “No Classification without Representation: Assessing Geodiversity Issues in Open Data Sets for the Developing World.” stat 1050 (2017): 22.
3.Torralba, Antonio, and Alexei A. Efros. “Unbiased look at dataset bias.” Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on. IEEE, 2011.
4.Barocas, Solon, and Andrew D. Selbst. “Big data’s disparate impact.” Cal. L. Rev. 104 (2016):671.
5.Sweeney, Latanya. “Discrimination in Online Ad Delivery.” Communications of the ACM 56.5(2013): 44-54.
6.Barocas, Solon, and Andrew D. Selbst. “Big data’s disparate impact.” Cal. L. Rev. 104 (2016):671.
7.https://www.newyorker.com/magazine/2017/04/03/ai-versus-md
8.https://thewalrus.ca/how-we-made-ai-as-racist-and-sexist-as-humans/
