

预测未知,一直是人类十分向往的能力。远不说国人熟悉的周易八卦、唐代道士编写的《推背图》,还有西方人熟知的占星术、中世纪流行起来的塔罗牌,近的比如说当年根据 “2012世界末日”这一玛雅预言影响下出现的全民狂热和商业狂欢,依然让我们记忆犹新。
现在“不问苍生问鬼神”的时代已经过去,我们对物理世界及社会经济的确定性的、经验性的甚至概率性的预测都已轻车熟路。但比如说像“蝴蝶效应”描述的高度复杂的、超多变量以及超大数据量的预测,人类还是束手无策么?
答案并不是。
近日,我国武汉新型冠状病毒疫情的爆发引起世界卫生组织和全球多地卫生机构的密切关注。其中,《连线》杂志报道了“一家加拿大公司BlueDot通过AI监测平台率先预测和发布武汉出现传染疫情”的新闻,得到国内媒体的广泛关注。这似乎是我们在“预测未来”这件事上最想看到的成果——借助大数据沉淀基础和AI的推断,人类似乎正能够揣摩“天意”,揭示出原本深藏于混沌之中的因果规律,从而在天灾降临前试图挽救世界。
今天我们就从传染病预测出发,看看AI是如何一步步走向“神机妙算”的。
谷歌GFT频喊“狼来了”:流感大数据的狂想曲
用AI预测传染病显然不是Bluedot的专利,其实早在2008年,今天的AI“强手”谷歌,就曾进行过一次不太成功的尝试。

2008年谷歌推出一个预测流感流行趋势的系统——Google Flu Trends(谷歌流感趋势,以下简称GFT)。GFT一战成名是在2009年美国H1N1爆发的几周前,谷歌工程师在《Nature》杂志上发表了一篇论文,通过谷歌累积的海量搜索数据,成功预测H1N1在全美范围的传播。就流感的趋势和地区分析中,谷歌用几十亿条检索记录,处理了4.5亿个不同的数字模型,构造出一个流感预测指数,其结果与美国疾病控制和预防中心(CDC)官方数据的相关性高达97%,但要比CDC提前了整整2周。
在疫情面前,时间就是生命,速度就是财富,如果GFT能一直保持这种“预知”能力,显然可以为整个社会提前控制传染病疫情赢得先机。
然而,预言神话没有持续多久。2014年,GFT又再次受到媒体关注,但这一次却是因为它糟糕的表现。研究人员2014年又在《Science》杂志发布 “谷歌流感的寓言:大数据分析的陷阱” 一文,指出在2009年,GFT没有能预测到非季节性流感A-H1N1。从2011年8月到2013年8月的108周里,GFT有100周高过了CDC报告的流感发病率。高估了多少呢?在2011-2012季,GFT预测的发病率是CDC报告值的1.5倍多;而到2012-2013季,GFT预测流感发病率已是CDC报告值的2倍多。
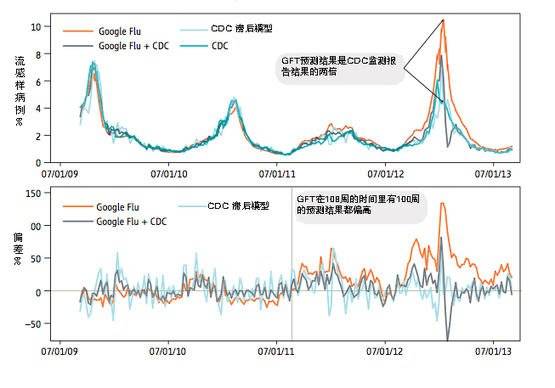
(图表来自The Parable of Google Flu: Traps in Big Data Analysis | Science,2014)
尽管GFT在2013年调整了算法,并回应称出现偏差的罪魁祸首是媒体对GFT的大幅报道导致人们的搜索行为发生了变化,GFT预测的2013-2014季的流感发病率,仍然高于CDC报告值1.3倍。并且研究人员前面发现的系统性误差仍然存在,也就是“狼来了”的错误仍然在犯。
到底GFT遗漏了哪些因素,让这个预测系统陷入窘境?
根据研究人员分析,GFT的大数据分析出现如此大的系统性误差,其收集特征和评估方法可能存在以下问题:
一、大数据傲慢(Big Data Hubris)
所谓“大数据傲慢”,就是谷歌工程师给出的前提假设,即,通过用户搜索关键词得到的大数据包含的即是流感疾病的全数据收集,可以完全取代传统数据收集(采样统计),而不是其补充。也就是GFT认为“采集到的用户搜索信息”数据与 “某流感疫情涉及的人群”这个总体完全相关。
这一 “自大”的前提假设忽视了数据量巨大并不代表数据的全面和准确,因而出现在2009年成功预测的数据库样本不能涵盖在之后几年出现的新的数据特征。也是因为这份“自负”,GFT也似乎没有考虑引入专业的健康医疗数据以及专家经验,同时也并未对用户搜索数据进行“清洗”和“去噪”,从而导致此后流行病发病率估值过高但又无力解决的问题。
二、搜索引擎演化
同时搜索引擎的模式也并非一成不变的,谷歌在2011年之后推出“推荐相关搜索词”,也就是我们今天很熟悉的搜索关联词模式。
比如针对流感搜索词,给出相关寻求流感治疗的list,2012年后还提供相关诊断术语的推荐。研究人员分析,这些调整有可能人为推高了一些搜索,并导致谷歌对流行发病率的高估。
举例来说,当用户搜索“喉咙痛”,谷歌会在推荐关键词给出“喉咙痛和发烧”、“如何治疗喉咙痛”等推荐,这时用户可能会出于好奇等原因进行点击,造成用户使用的关键词并非用户本意的现象,从而影响GFT搜集数据的准确性。

而用户的搜索行为反过来也会影响GFT的预测结果,比如媒体对于流感流行的报道会增加与流感相关的词汇的搜索次数,进而影响GFT的预测。这就像量子力学家海森堡指出的,在量子力学中存在的“测不准原理”说明的一样,“测量即干涉”,那么,在充斥媒体报道和用户主观信息的搜索引擎的喧嚣世界里,也同样存在“预测即干涉”悖论。搜索引擎用户的行为并不完全是自发产生,媒体报道、社交媒体热点、搜索引擎推荐甚至大数据推荐都在影响用户心智,造成用户特定搜索数据的集中爆发。
为什么GFT的预测总是偏高?根据这一理论,我们可以知道,一旦GFT发布的流行病预测指数升高,立刻会引发媒体报道,从而导致更多相关信息搜索,从而又强化GFT的疫情判断,无论如何调整算法,也改变不了“测不准”的结果。
三、相关而非因果
研究人员指出,GFT的根源问题在于,谷歌工程师并不清楚搜索关键词和流感传播之间到底有什么因果联系,而只是关注数据之间的——统计学相关性特征。过度推崇“相关”而忽略“因果”就会导致数据失准的情况。
比如,以“流感”为例,如果一段时间该词搜索量暴涨,可能是因为推出一部《流感》的电影或歌曲,并不一定意味着流感真的在爆发。
一直以来,尽管外界一直希望谷歌能够公开GFT的算法,谷歌并没有选择公开。这让很多研究人员质疑这些数据是否可以重复再现或者存在更多商业上的考虑。他们希望应该将搜索大数据和传统的数据统计(小数据)结合起来,创建对人类行为更深入、准确的研究。
显然,谷歌并没有重视这一意见。最终在2015年GFT正式下线。但其仍在继续收集相关用户的搜索数据,仅提供给美国疾控中心以及一些研究机构使用。
为什么BlueDot率先成功预测:AI算法与人工分析的协奏曲
众所周知,谷歌在当时已经在布局人工智能,2014年收购DeepMind,但依然保持它的独立运营。同时,谷歌也没有GFT再投入更多关注,因此也并未考虑将AI加入到GFT的算法模型当中,而是选择了让GFT走向“安乐死”。
几乎在同一时期,今天我们所见到的BlueDot诞生。
BlueDot是由传染病专家卡姆兰·克汗(Kamran Khan)建立流行病自动监测系统,通过每天分析65种语言的约10万篇文章,来跟踪100多种传染病爆发情况。他们试图用这些定向数据收集来获知潜在流行传染病爆发和扩散的线索。
BlueDot一直使用自然语言处理(NLP)和机器学习(ML)来训练该“疾病自动监测平台”,这样不仅可以识别和排除数据中的无关“噪音”,比如,系统识别这是蒙古炭疽病的爆发,还仅仅是1981年成立的重金属乐队“炭疽”的重聚。又比如GFT仅仅将“流感”相关搜索的用户理解为可能的流感病患者,显然出现过多不相关用户而造成流行病准确率的高估。这也是BlueDot区别于GFT在对关键数据进行甄别的优势之处。
就像在这次在新型冠状病毒疫情的预测中, 卡姆兰表示,BlueDot通过搜索外语新闻报道,动植物疾病网络和官方公告来找到疫情信息源头。但该平台算法不使用社交媒体的发布内容,因为这些数据太过杂乱容易出现更多“噪音”。

关于病毒爆发后的传播路径预测,BlueDot更倾向于使用访问全球机票数据,从而更好发现被感染的居民的动向和行动时间。在1月初的时候,BlueDot也成功预测了新型冠状病毒从武汉爆发后,几天之内从武汉扩散至北京、曼谷、汉城及台北。
新冠病毒爆发并非是BlueDot的第一次成功。在2016年,通过对巴西寨卡病毒的传播路径建立AI模型的分析,BlueDot成功地提前六个月预测在美国佛罗里达州出现寨卡病毒。这意味着BlueDot的AI监测能力甚至可以做到预测流行病的地域蔓延轨迹。
从失败到成功,BlueDot和谷歌GFT之间究竟存有哪些差异?
一、预测技术差异
之前主流的预测分析方法采取的是数据挖掘的一系列技术,其中经常用到的数理统计中的“回归”方法,包括多元线性回归、多项式回归、多因Logistic回归等方法,其本质是一种曲线的拟合,就是不同模型的“条件均值”预测。这也正是GFT所采用的预测算法的技术原理。
在机器学习之前,多元回归分析提供了一种处理多样条件的有效方法,可以尝试找到一个预测数据失误最小化且“拟合优度”最大化的结果。但回归分析对于历史数据的无偏差预测的渴求,并不能保证未来预测数据的准确度,这就会造成所谓的“过度拟合”。
据北大国研院教授沈艳在《大数据分析的光荣与陷阱——从谷歌流感趋势谈起》一文中分析,谷歌GFT确实存在“过度拟合”的问题。也就是在2009年GFT可以观察到2007-2008年间的全部CDC数据,采用的训练数据和检验数据寻找最佳模型的方法所参照的标准就是——不惜代价高度拟合CDC数据。
所以,在2014年的《Science》论文中指出,会出现GFT在预测2007-2008年流感流行率时,存在丢掉一些看似古怪的搜索词,而用另外的5000万搜索词去拟合1152个数据点的情况。2009年之后,GFT要预测的数据就将面临更多未知变量的存在,包括它自身的预测也参与到了这个数据反馈当中。无论GFT如何调整,它仍然要面对过度拟合问题,使得系统整体误差无法避免。
BlueDot采取了另外一项策略,即医疗、卫生专业知识和人工智能、大数据分析技术结合的方式,去跟踪并预测流行传染病在全球分布、蔓延的趋势,并给出最佳解决方案。

BlueDot主要采用自然语言处理和机器学习来提升该监测引擎的效用。随着近几年算力的提升以及机器学习,从根本上彻底改变了统计学预测的方法。主要是深度学习(神经网络)的应用,采用了“反向传播”的方法,可以从数据中不断训练、反馈、学习,获取“知识”,经过系统的自我学习,预测模型会得到不断优化,预测准确性也在随着学习而改进。而模型训练前的历史数据输入则变得尤为关键。足够丰富的带特征数据是预测模型得以训练的基础。经过清洗的优质数据和提取恰当标注的特征成为预测能否成功的重中之重。
二、预测模式差异
与GFT完全将预测过程交给大数据算法的结果的方式不同,BlueDot并没有完全把预测交给AI监测系统。BlueDot是在数据筛选完毕后,会交给人工分析。这也正是GFT的大数据分析的“相关性”思维与BlueDot的“专家经验型”预测模式的不同。
AI所分析的大数据是选取特定网站(医疗卫生、健康疾病新闻类)和平台(航空机票等)的信息。而AI所给出的预警信息也需要相关流行病学家的再次分析才能进行确认是否正常,从而评估这些疫情信息能否第一时间向社会公布。
当然,就目前这些案例还不能说明BlueDot在预测流行病方面已经完全取得成功。首先,AI训练模型是否也会存在一些偏见,比如为避免漏报,是否会过分夸大流行病的严重程度,因而再次出现“狼来了”的问题?其次,监测模型所评估的数据是否有效,比如BlueDot谨慎使用社交媒体的数据来避免过多的“噪音”?

幸而BlueDot作为一家专业的健康服务平台,他们会比GFT更关注监测结果的准确性。毕竟,专业的流行病专家是这些预测报告的最终发布人,其预测的准确度直接会影响其平台信誉和商业价值。这也意味着,BlueDot还需要面临如何平衡商业化盈利与公共责任、信息开放等方面的一些考验。
AI预测流行病爆发,仅仅是序曲……
“发出第一条武汉冠状病毒警告的是人工智能?”媒体的这一标题确实让很多人惊讶。在全球一体化的当下,任何一地流行疾病的爆发都有可能短时间内传遍全球任何一个角落,发现时间和预警通报效率就成为预防流行疾病的关键。
如果AI能够成为更好的流行病预警机制,那不失为世界卫生组织(WHO)以及各国的卫生健康部门进行流行病预防机制的一个办法。
那这又要涉及到这些机构组织如何采信AI提供的流行病预报结果的问题。未来,流行病AI预测平台还必须提供流行病传染风险等级,以及疾病传播可能造成的经济、政治风险的等级的评估,来帮助相关部门做出更稳妥的决策。而这一切,仍然需要时间。这些组织机构在建立快速反应的流行病预防机制中,也应当把这一AI监测系统提上日程了。
可以说,此次AI对流行病爆发提前成功地预测,是人类应对这场全球疫情危机的一抹亮色。希望这场人工智能参与的疫情防控的战役只是这场持久战的序曲,未来应该有更多可能。比如,主要传染病病原体的AI识别应用;基于主要传染病疫区和传染病的季节性流行数据建立传染病AI预警机制;AI协助传染病爆发后的医疗物资的优化调配等。这些让我们拭目以待。
