

试想一下,一个静谧的午夜,你和家人正在熟睡,家中突然响起毛骨悚然的笑声,时远时近,这困扰了大人,惊吓了孩子。这些怪笑是Alexa发出来的。作为亚马逊的主推产品,Alexa的这次故障让许多用户陷入恐慌之中。
目前,亚马逊方面并没有对此次故障的原因进行详尽解释,并且它强调这是在“极少数情况”下才会发生的。尽管网上反映的问题代表不了使用Echo的数千万用户,但可以看出亚马逊对此事的态度其实不以为意。
类似的情况,在聊天机器人身上已经不是第一次发生。两年前,微软在Twitter上的聊天机器人Tay变成了“种族主义者”,不到一年,它的后续产品Zo又再次出现问题。Zo认为古兰经里描述的内容“非常暴力”,并且它认为抓住本·拉登是“不止一个政府多年情报收集”的结果。

Zo发表的不宜言论
之前,Facebook也关闭了虚拟助理M,团队相关成员被派遣到其他部门任职。聊天机器人的发展,看起来道阻且长。
聊天机器人变成“人工智障”?
“和机器人有着最自然的对话,它将一切任务都执行得完美无瑕,我们可能都希望能生活在这样的世界里。这一路走来确实不容易,而且说实话我们已经发展得很快了。”Politibot的Suárez认为,“但不幸的是,我们还没有达到那个理想的生活状态,还要好几年,机器人才能好到普罗大众都能接受。”
然而,现实却远不及Suárez的预期,聊天机器人依然存在着众多问题。2016年,Facebook Messenger开放其程序接口后,收到的用户反馈很少。众多机构确实可以在短时间内拥有自己的智能聊天机器人,但当此类机器人无人类干预时,应答失败率高达 70%,用户体验更是相当糟糕。
从“图灵测试”到Eliza的精神治疗,聊天机器人发展至今已经走过了近70年,在漫长的发展历程中,聊天机器人并未得到真正的普及,现今依然存在着诸多弊病。
是谁让聊天机器人变成了这样?智能相对论(ID:aixdlun)认为,是人类,更是机器本身。部分核心技术及适配性问题,依然是聊天机器人的阿喀琉斯之踵。
1. 复杂语言识别困难
现在的聊天机器人,对话界面主要依赖于语音识别,从而根据用户命令做出便捷迅速的反应,比如“下午三点去参加会议”“今天的天气怎样”等。
语言作为一种主观性较强的表达方式,人们说话的规则可以说是千变万化的。这和电脑程序不同,人们表达不会完全受制于规则,能够自由的遣词造句,并以此来传递信息。除了地方方言外,每个人也会有自己独特的表达方式,例如心照不宣的“暗语”,或者某些特定的“梗”。这就需要聊天机器人“去陌生化”,结构化语言的系统将难以满足大量用户的需求,这对聊天机器人的系统提出了更高的要求。
以Richard S.Wallac设计的Alice聊天机器人为例,其在中文处理上就存在一些问题。这是因为汉语不像英语等语言,用空格或其他标记分词,这就加大了Alice对中文支持的难度。此外,其对于汉语分词采用的一般匹配法、词频统计法、同义句的处理等方面也存在着许多技术难题。
“人工智障”般的聊天机器人
2. 个性化适配之痛
个性化适配的问题体现在两个方面,一方面人机信任是聊天机器人个性化发展的一个攻坚点。调查显示,许多公司领导对于聊天机器人处理待办事项是并不看好的,聊天机器人程序化的语言会让许多人觉得“乏味”“没有人气”,这也是公司助理一职并未被取代的原因。
另一方面,聊天机器人很容易对人的需求产生误读。比如对Siri发出“区块链”的指示,Siri提供的是关于区块链的百度百科,这与用户想要了解区块链的最新发展动态的初衷大相径庭。
目前聊天机器人语音识别主要基于语音识别的基本架构、声学模型、语言模型并进行解码,而真正通过用户画像来实现个性化适配的聊天机器人少之又少。其实,不同用户的性格、特点、知识层次都不相同。如果有预设的用户画像,那出现适配失误的可能性也会大大减小。
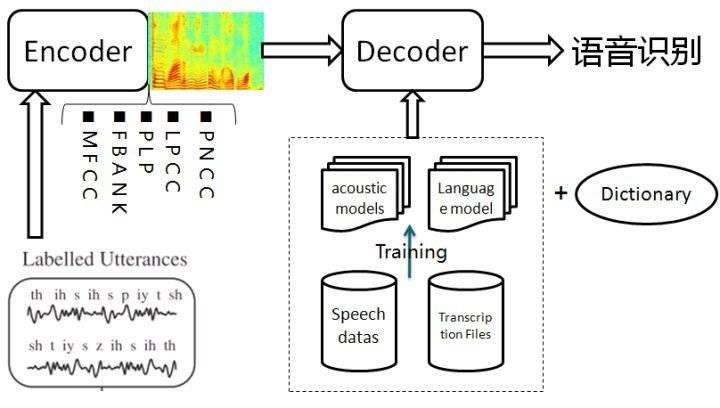
当前语音识别的通常模式
目前来看,机器学习能够做到的事情,大体主要还是字符识别(OCR)、语音识别、人脸识别这一类,这些称之为“识别系统”。这些系统的问题在于难以变通,简单的语音识别难以真正为用户提供较为复杂的辅助工作,线性的识别方式也难以适用于更开放的应用场景。
3. 隐私安全终成隐忧
最近,Facebook被曝史上最大数据泄露案,特朗普被指利用AI竞选成功,这也让更多的聊天机器人用户对自身的隐私感到担忧。“Alexa发笑”事件中,亚马逊对于事件原因闪烁其词,似乎用户数据已经进入了“围墙花园”的模式。语音分析和人工智能软件存在于一个黑匣子中,而这些软件只有硅谷的开发人员才能真正理解。很难想象,如果将一切的智能家居与聊天机器人连接起来时,涉及到的数据、信息都存储在一个用户无法拥有也无法控制的计算机上,这是一件多么可怕的事。
作为语音识别领域的领军人物,微软于2016年也仅仅将错误率控制在5.8%左右。可是随着人工智能进一步拓展到金融、医疗等领域,1%的错误率导致的可能就是财产的损失和生命的安全。
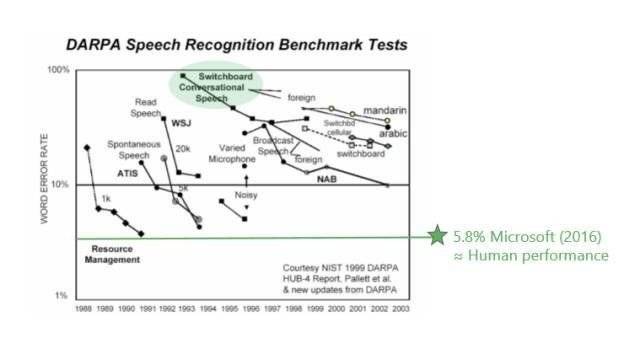
微软语音识别错误率(2016年)
此外,配套设施的不完善难以让聊天机器人发展成了一个严密的体系,这使得初次试水的用户对此颇有微词。聊天机器人何时能够完善到能够大范围普及,这也是开发聊天机器人的公司需要认真思考的问题。
聊天机器人或许需要“洗心革面”
曾经火遍全球的索菲娅机器人,前段时间也摊上大事了。Yan LeCun(机器人专家)指出索菲娅与人类堪称完美的聊天对话其实是一场彻头彻尾的骗局,以目前人工智能的技术来看,此种对话是不可能实现的。
而在2018年年初,Facebook关闭了虚拟助理M,成了压死骆驼的最后一根稻草。许多互联网公司对聊天机器人已经不感兴趣了,聊天机器人的发展也走进了死胡同。智能相对论(ID:aixdlun)认为,可以从三个方面“洗心革面”。
1. 塑造聊天机器人的“独立三观”
能够独立表达喜欢、不喜欢和偏好的性格,在聊天的过程中展示出诚实和值得信任等可贵品质,是塑造聊天机器人“独立三观”的重要体现。正如聊天机器人被引入日常生活,我们还能训练机器人去识别我们的语言,挖掘我们的喜好,甚至还能分析我们的口音,推测我们的情绪。
有一个典型的例子:通过自然语言和情感分析,Quartz公司尝试着让Quartzy来指导特定用户做面包。Quartzy会以一种友好且有趣的方式和用户聊聊“怎么做一个免揉面包”,一旦用户完成了第一个步骤,Quartzy会在大概12小时后,用Facebook Messenger给用户“叮”一个通知,提醒用户完成后续的步骤。这是聊天机器人独立三观的一个体现,当然希望以后这样的尝试会更加普及。
2. 从“鹦鹉学舌”到“乌鸦喝水”
“鹦鹉学舌”是人类语言的模仿行为,由数据驱动的聊天机器人也可以探索出类似的方式。而“乌鸦喝水”则是一个完全自主行为,其含括了感知、认知、推理、学习和执行,这是聊天机器人朝想象力、创造力更高层次的进阶。目前,要真正实现聊天机器人的“乌鸦喝水”,主要从这两个方面来努力:
一方面,让人工智能在自动学习中“更聪明”。 伊恩·古德费洛做过一个实验,用两个神经网络进行数字版的“猫鼠游戏”——一个负责“造假”,一个负责“验真”,从而在对抗中不断提高。首先,依据“见过”的图片生成新图片,让聊天机器人总结规律、发挥想象力和创造力;其次,判别某张图片是否是真实事物,这就要靠聊天机器人通过训练积累“经验”。
另一方面,建立更加丰富的知识图谱。知识图谱的建立需要从静态和动态两个方面出发,真正将聊天对话场景从垂直领域拓展到开放领域。同时,构建知识图谱的重点在于语义理解、知识表示、QA、智能对话和用户建模。
3. 找到更多远的盈利模式
聊天机器人作为一个虚拟助理,其存在的目的是为了给人类提供便利。聊天机器人主要分为两种:单纯聊天的机器人以及垂直领域的定制机器人,如小i机器人就衍生出了全渠道、跨领域智能客服机器人、智能呼叫中心解决方案、智能营销解决方案、智能语音交互解决方案等多个发展方向。当下,聊天机器人主要利用于内置商业场景中,如用机器客服代替人工客服。
事实上,目前业内对聊天机器人盈利模式的探索还远远不够。作为人工智能产品的重要代表,其在聊天机器人+原生内容、利用聊天机器人做联盟网络营销、用聊天机器人做用户调研等方面是大有可为的。这显然不仅仅是聊天机器人或者个别互联网公司的任务,也是整个行业的义务。
