

备受期待的谷歌 Gemini 技术报告完整版,今天终于出炉了。
两周前,人们兴奋于谷歌提出的“原生多模态大模型”Gemini,其宣称超越 GPT-4 的强大性能,以及对于图像、视频等领域的理解能力让人们似乎看到了未来。不过由于谷歌演示的 demo 涉嫌夸大效果,Gemini 又很快陷入了争议。
但作为生成式 AI 领域最近的重要进展,人们对于 Gemini 的期待越来越高,有团队很快进行研究并发布测试论文。今天发布的 64 页技术报告,或许可以为我们的许多疑惑进行更加直观的解释。
这篇技术报告《Gemini: A Family of Highly Capable Multimodal Models》作者包括 Jeff Dean、Oriol Vinyals、Koray Kavukcuoglu、Demis Hassabis 等一众谷歌研究大佬,另外还有谢尔盖·布林这样的公司联合创始人。
论文链接:https://arxiv.org/abs/2312.11805
另外,该文章的作者数量也夺人眼球 ——941 个人,搞得 arXiv 网页都有点卡:
一页显示不过来。
从文章第 35 页起,谷歌开始罗列所有“贡献者”,从 Team Leader 到主要贡献者,再到贡献者分门别类写到了第 45 页,看起来之前各路媒体说谷歌在 Gemini 上投入了大量工程师,的确是没说错。
谷歌表示,在每个任务方向上,人们对 Gemini 所做的贡献是同等重要的,名字按随机顺序列出。Gemini 是一项跨谷歌内部多团队的工作,成员来自 Google DeepMind、Google Research、Knowledge and Information、Core ML、Cloud、Labs 等部门。
此外还有提供了支持的团队和人(比如公司 CEO 桑达尔·皮查伊),以及没有列出的很多谷歌内部贡献者。
对此有人吐槽道,论文作者比解释技术写得还长,你这怕不是在水字数?
光是这些花费在这些工程师、科学家们身上的工资每年就有上亿美元。
在技术报告中,谷歌表示 Gemini 是一个多模态大模型体系,它在图像、音频、视频和文本理解方面表现出卓越的能力。Gemini 系列包括 Ultra、Pro 和 Nano 三个版本,适用于从复杂推理任务到移动设备的各种应用。
通过在大量基准的跑分表明,功能最强大的 Gemini Ultra 在 32 个基准中的 30 个中刷新了 SOTA(业内最佳)水平。谷歌特别指出,Gemini 是第一个在经过充分研究的考试基准 MMLU 上实现人类专家表现的模型。谷歌相信,Gemini 在跨模态推理和语言理解方面的突出能力将支持各种用例。
以下图所示的教育环境为例,老师画了一个滑雪者从斜坡上滑下的物理问题,学生试图进行解答。利用 Gemini 的多模态推理能力,该模型能够理解凌乱的笔迹,正确理解问题的表述,将问题和解决方案都转换为数学排版,识别学生在解决问题时出错的具体推理步骤,然后给出问题的正确解法。

图 1,笔记识别,解答物理问题。
Gemini 的推理能力展示了构建能解决更复杂多步骤问题的通用智能体的前景,比如谷歌基于 Gemini 提出了 AlphaCode 2。在移动设备上,Gemini Nano 在摘要、阅读理解、文本填充任务等任务中表现出色,也体现了推理、STEM、编码、多模态和多语言任务的能力。
在文章的技术解释部分中,谷歌概述了 Gemini 的模型架构、训练基础设施和训练数据集,对 Gemini 模型系列进行了详细评估,涵盖文本、代码、图像、音频和视频方面。谷歌讨论了模型审核与部署方法,最后也讨论了 Gemini 的更广泛影响、局限性及其潜在应用。
模型架构
Gemini 1.0 有三种尺寸 Ultra 、 Pro 以及 Nano ,如下所示:

-
Ultra:可以在各种高度复杂的任务中提供SOTA性能,包括推理和多模态任务。它还可以在TPU加速器上有效地进行大规模服务;
-
Pro:是谷歌在成本和延迟方面进行性能优化的模型,可在各种任务中提供良好的性能,并表现出强大的推理性能和广泛的多模态能力;
-
Nano:谷歌最高效的模型,专为在设备上运行而设计。谷歌训练了两个版本的 Nano,参数分别为 1.8B (Nano-1) 和 3.25B (Nano-2),分别针对低内存和高内存设备,采用 4 位量化进行部署,并提供一流的性能。
Gemini 的输入有多种形式,如文本、音频、图片、视频等,如下图2所示。值得一提的是,Gemini是原生多模态的。
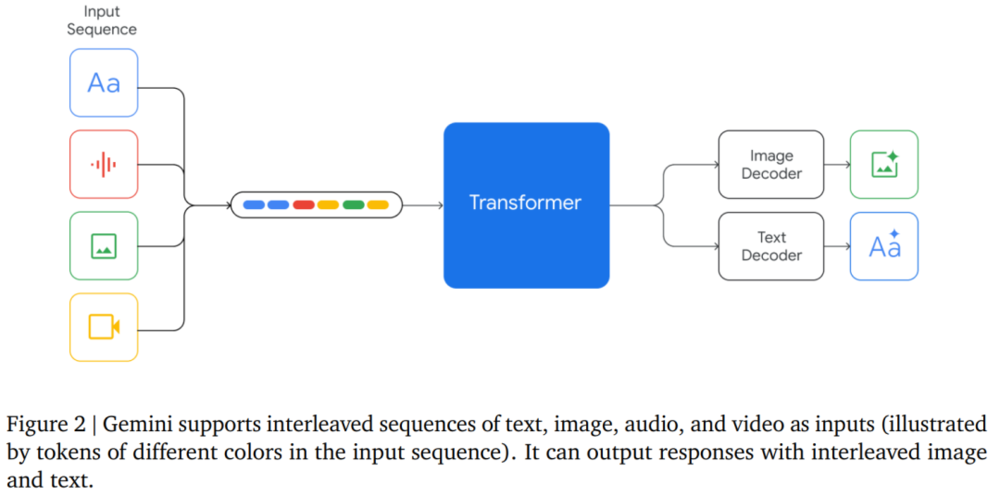
Gemini 的视频理解能力是通过将视频编码为大上下文窗口中的帧序列来完成的。视频帧或图像可以自然地与文本或音频交织,作为模型输入的一部分。Gemini 模型可以处理可变的输入分辨率,以便将更多的计算花费在需要细粒度理解的任务上。
此外,Gemini 可以直接从通用语音模型(USM)功能中摄取 16kHz 的音频信号。这使得模型能够捕获当音频被简单地映射到文本输入时通常会丢失的细微差别。
训练基础设施
谷歌使用 TPUv5e 和 TPUv4 训练 Gemini 模型,具体取决于模型的大小和配置。其中,训练 Gemini Ultra 使用跨多个数据中心的大量 TPUv4 加速器,相比于 PaLM-2,规模显著增加,带来了新的基础设施挑战。
增加加速器的数量会导致整个系统中硬件的平均故障间隔时间成比例地减少。因此,谷歌最大限度地减少了计划重新规划和抢占的比率,但实际上机器故障在如此大规模的硬件加速器中很常见。
TPUv4 加速器部署在 4096 个芯片的“SuperPod”中,每个芯片连接到一个专用光开关,可以在大约 10 秒内将 4x4x4 芯片cube动态重新配置为任意 3D 环面拓扑。对于 Gemini Ultra,谷歌为每个超级容器保留少量cube,以实现热备用和滚动维护。
TPU 加速器主要通过高速芯片间互连进行通信,但对于 Gemini Ultra,谷歌使用其集群内和集群间网络在多个数据中心中组合 SuperPod。
使用定期检查持久集群存储权重的传统方法,在这种规模下维持高吞吐量是不可能的。因此谷歌为 Gemini 使用了模型状态的冗余内存副本,并且在任何计划外的硬件故障中,Gemini 可以直接从完整的模型副本中快速恢复。与 PaLM 和 PaLM-2 相比,尽管使用的训练资源要大得多,但恢复速度显著加快。
最终,最大规模训练 job 的整体吞吐量从 85% 增加到 97%。
Gemini 模型是在多模态和多语言数据集上进行训练的,预训练数据集使用来自网络文档、书籍和代码的数据,包括图像、音频和视频数据。谷歌使用了 SentencePiece tokenizer,并发现在整个训练语料库的大样本上训练 tokenizer 可以提高推断词汇量,从而提高模型性能。
此外,谷歌还使用启发式规则和基于模型的 tokenizer 对所有数据集应用质量过滤器,并执行安全过滤以删除有害内容。
评估
Gemini 模型本质上是多模态模型,跨文本、图像、音频和视频数据联合训练。一个悬而未决的问题是,这种联合训练是否能够产生一种在每个领域都具有强大能力的模型 —— 即使与针对单个领域进行定制的模型相比也是如此。谷歌进行了一系列的评估实验证明:Gemini 在广泛的文本、图像、音频和视频基准上实现了新的 SOTA 水平。
文本
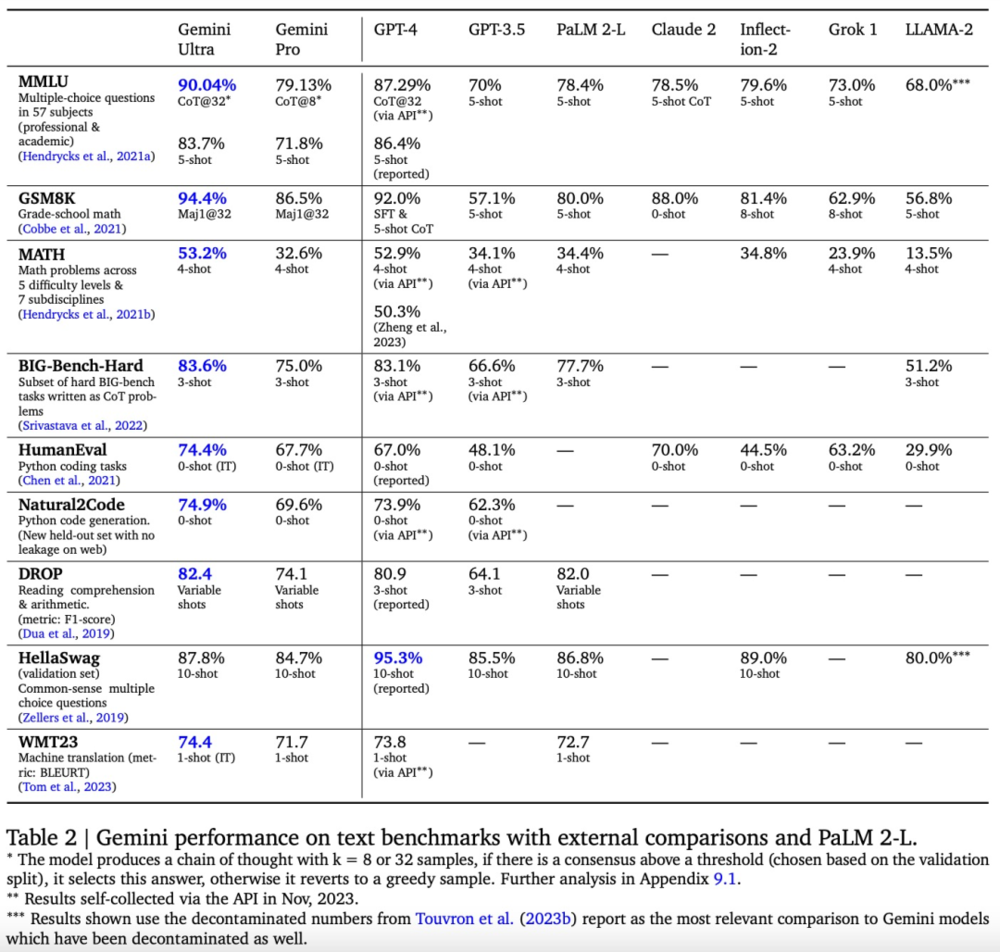
谷歌将 Gemini Pro 和 Gemini Ultra 与多个外部 LLM 以及谷歌之前的最佳模型 PaLM 2 进行了一系列基于文本的学术基准比较,涵盖推理、阅读理解、STEM 和编码。实验结果如下表 2 所示:
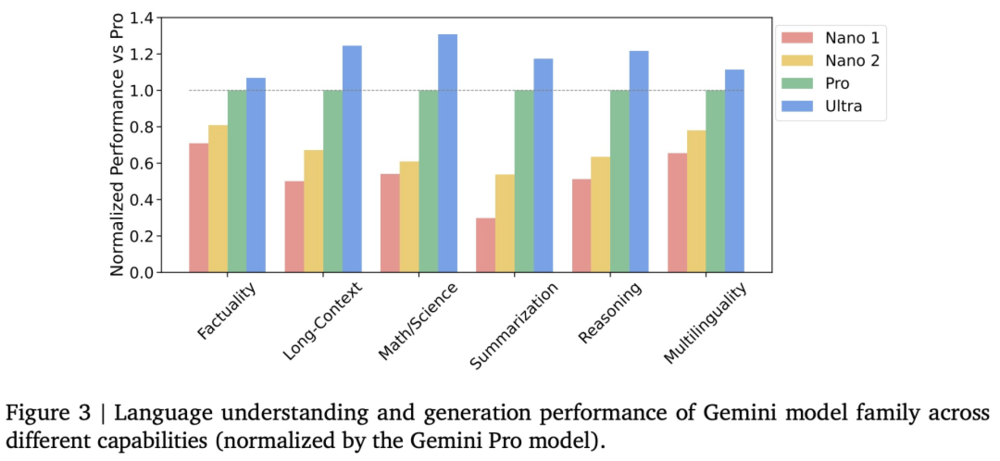
谷歌还通过在六种不同能力的 50 多个基准上进行评估,检查了 Gemini 模型的能力趋势,涵盖:
-
开卷 / 闭卷检索和问答任务,要求“事实性”;
-
长上下文摘要、检索和问答任务;
-
数学 / 科学问题解决、定理证明和考试;
-
需要算术、科学和常识的“推理”任务;
-
用多种语言进行翻译、摘要和推理的“多语言”任务。
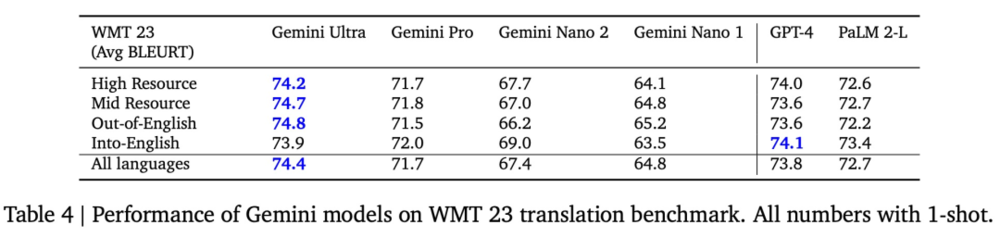
评估结果如下图表所示:

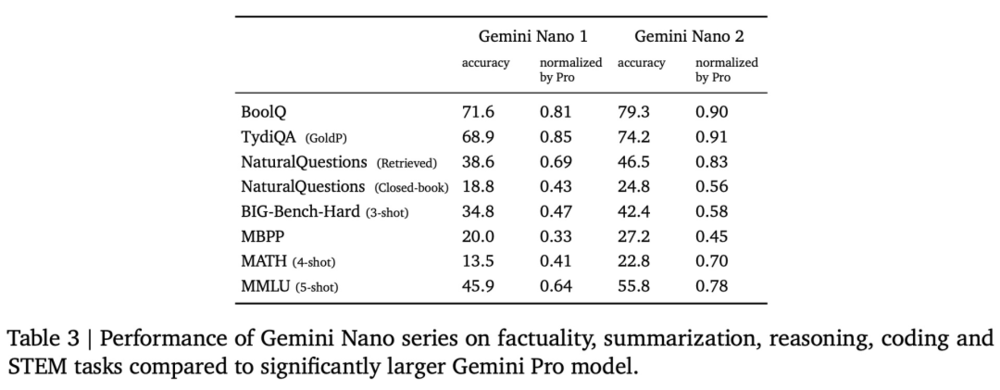
下表 3 更深入地探讨了 Gemini 在特定的事实、编码、数学 / 科学和推理任务上的性能。其中,Gemini Nano-1 和 Gemini Nano-2 的模型大小分别为 1.8B 和 3.25B。
值得一提的是,经过指令调整的 Gemini Pro 模型在一系列功能上表现出巨大的改进:

多模态
Gemini 模型是从头开始以多模态为目标构建的。它表现出了独特的能力,可以将跨模态的功能(例如,从表格、图表或图形中提取信息和空间布局)与语言模型的强大推理能力(如先进的推理能力)无缝地结合起来。
如图 5 和图 12 中的示例所示,这些模型在识别输入内容中的细粒度细节、跨空间和时间聚合上下文,以及将这些功能应用于时间相关的视频序列方面也表现出强大的能力。
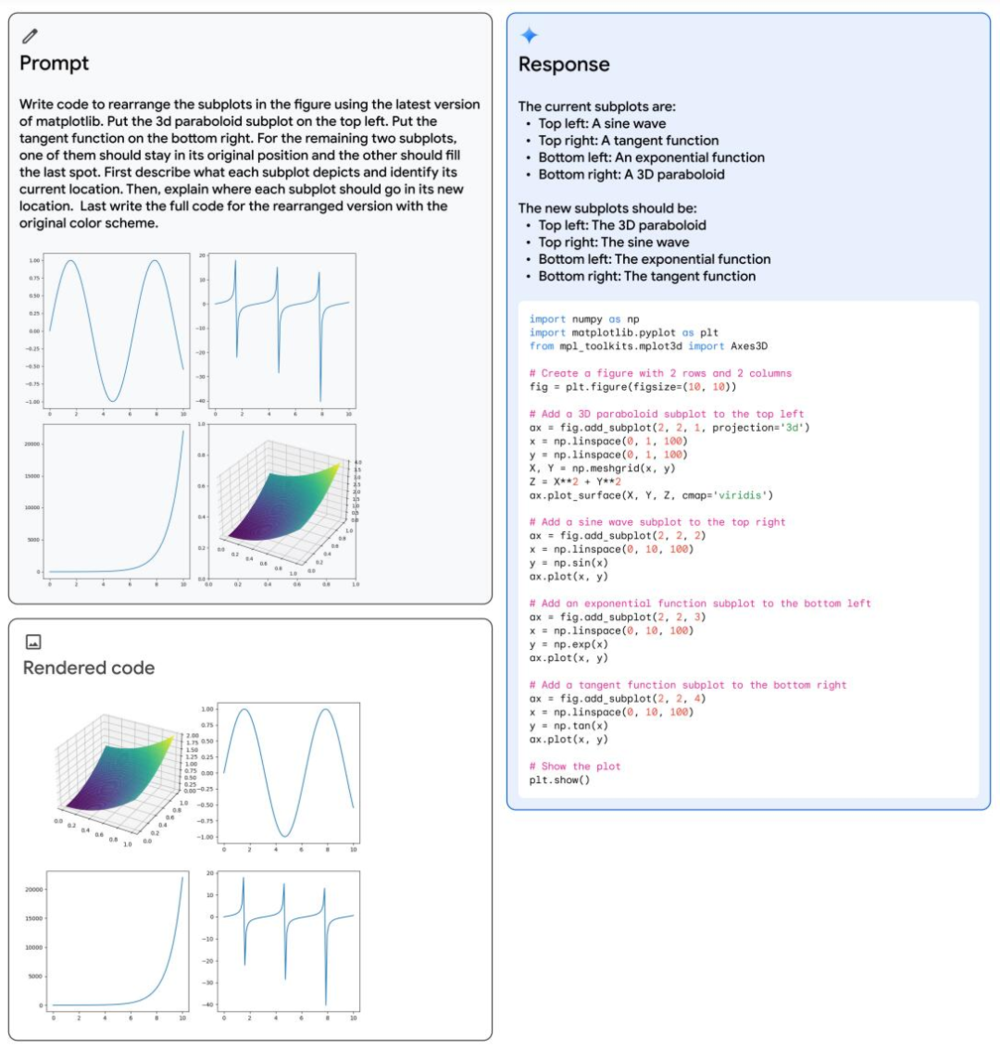
图 5、Gemini 的多模态推理功能可生成用于重新排列子图的 matplotlib 代码。
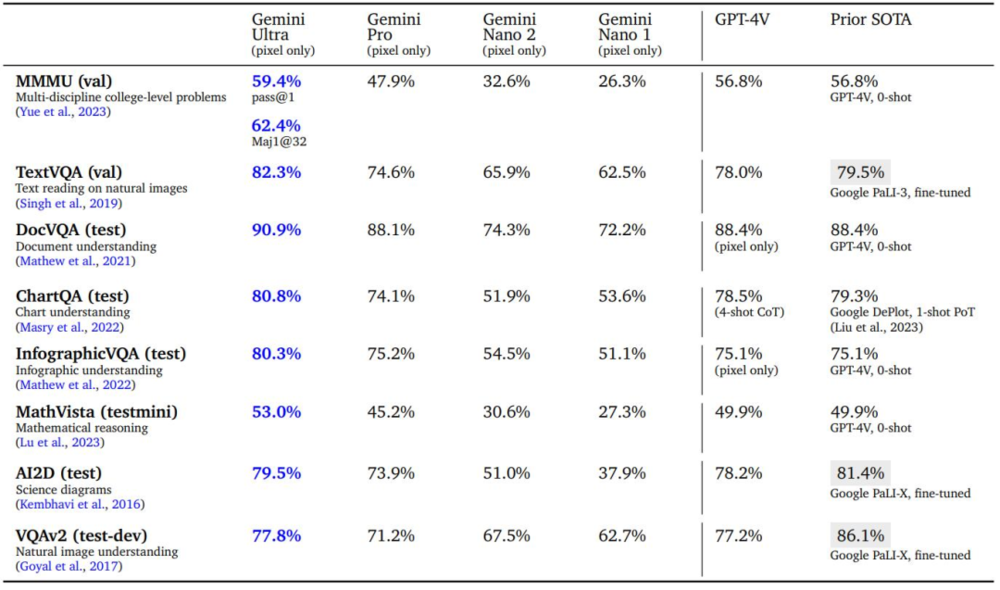
表 7、Gemini Ultra 在图像理解基准上的能力。
谷歌发现,Gemini Ultra 在各种图像理解基准测试中都是最先进的。
Gemini 模型还能够同时跨模态和理解多种语言。
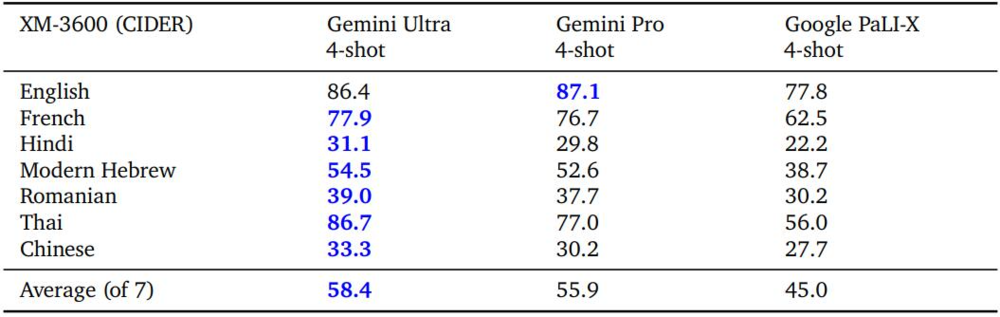
表 9、多语言图像理解。
Gemini Ultra 在各种 few-shot 视频字幕任务以及 zero-shot 视频问答任务上取得了最先进的结果。
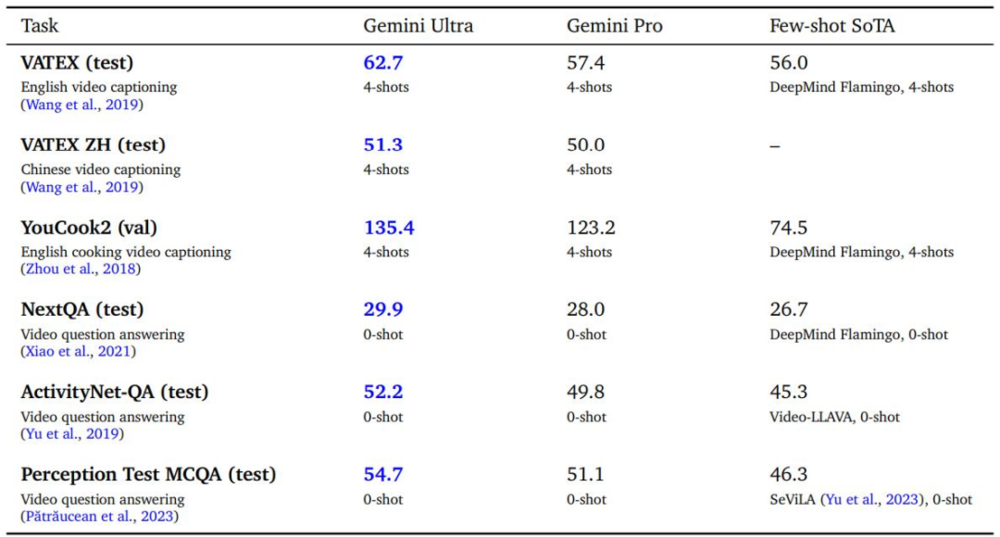
表 10、在选定的学术基准上跨任务和语言的 few-shot 视频理解。
图 6 显示了 one-shot 情况下的图像生成示例。

图 6、图像生成。在给出由图像和文本组成的提示的情况下,Gemini 可以输出与文本交错的多个图像。
有关语音理解能力,表 11 表明,无论是在英语还是多语言测试集上,Gemini Pro 模型在所有 ASR(语音识别)和 AST(自动语音翻译)任务中显著优于 USM 和 Whisper 模型。
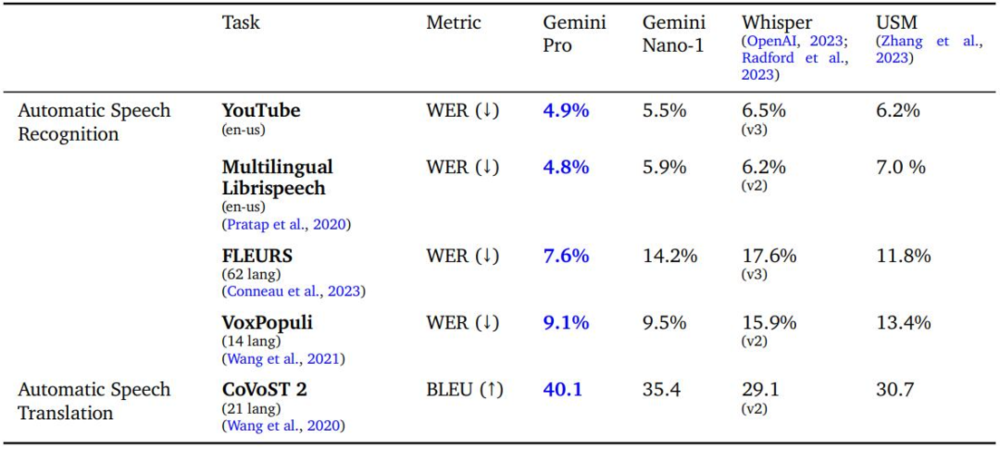
表 11、ASR 和 AST 选定基准的语音评估结果。
安全性
谷歌表示,在 Gemini 模型的开发过程中遵循了结构化方法进行负责任的部署,以便识别、衡量和管理大模型的可预见社会影响,这与 Google 人工智能技术的先前版本一致。

结语
谷歌在技术报告中表示,目前有关 Gemini 大模型的各种测试和用例,可能只涉及了其潜力的很小一部分。谷歌期待更多公司在更多场景上使用新的模型。
Gemini 为谷歌开发一个大规模、模块化的系统,实现最大泛化能力的目标提供了坚实基础。
