

去年夏天,一名联邦法官对纽约市一家律师事务所处以 5,000 美元的罚款,原因是一名律师使用人工智能工具 ChatGPT 起草了一起人身伤害案件的摘要。文本中充满了虚假信息,包括超过六个完全捏造的过去案例,旨在为人身伤害诉讼建立判例。
斯坦福大学(Stanford University)和耶鲁大学(Yale University)的研究人员在最近对三种流行的大语言模型(LLM)的研究预印本中发现,类似的错误在人工智能生成的法律输出中非常普遍。当生成式 AI 模型产生与现实不符的响应时,有一个术语:“幻觉(hallucination)”。
幻觉通常被描述为人工智能的一个技术问题,一个勤奋的开发人员最终会解决的问题。但许多机器学习专家并不认为幻觉是可以修复的,因为它源于LLMs只是在做他们被开发和训练应该做的事情:尽可能地响应用户提示。
根据一些人工智能研究人员的说法,真正的问题存在于我们的共同想法——对这些模型是什么以及如何使用它们的决定。研究人员表示,为了减轻幻觉,生成式人工智能工具必须与事实核查系统配对,避免任何不受监督的聊天机器人。
许多与人工智能幻觉有关的冲突都源于营销和炒作。科技公司将他们的LLM描绘成数字瑞士军刀,能够解决无数问题或取代人类工作。但是应用在错误的设置中,这些工具就会失败。聊天机器人为用户提供了不正确且可能有害的医疗建议,媒体机构发布了人工智能生成的文章,其中包括不准确的财务指导,具有人工智能界面的搜索引擎发明了虚假引文。随着越来越多的人和企业依赖聊天机器人来获取事实信息,他们编造事情的倾向变得更加明显和具有破坏性。
但今天的 LLM 从来都不是为了纯粹准确而设计的。它们被创造出来是为了创造——为了生成——亚利桑那州立大学(Arizona State University)研究人工智能的计算机科学教授Subbarao Kambhampati说。“现实情况是:没有办法保证所生成内容的真实性,”他解释说,并补充说,所有计算机生成的“创造力在某种程度上都是幻觉”。
(译者注:译者一直强调GenAI的应用场景选择的一个最重要的原则是:创意大于准确性。当前有人建议你将GenAI应用于数据分析的时候,请三思。)
在一月份发布的一项研究预印本中,新加坡国立大学的三名机器学习研究人员提出了一个证据,证明在大型语言模型中,幻觉是不可避免的。该证明应用了学习理论中的一些经典结果,例如康托尔的对角化论证(Cantor’s diagonalization argument),以证明 LLM 根本无法学习所有可计算函数。换句话说,它表明总会有超出模型能力的可解决的问题。
“对于任何大语言模型来说,现实世界中总有一部分是它无法学习的,在那里它不可避免地会产生幻觉。”该研究的合著者Ziwei Xu,Sanjay Jain和Mohan Kankanhalli在给《科学美国人》的一封联合电子邮件中写道。
尽管这个证明看起来是准确的,Kambhampati说,但它提出的某些难题总能难倒计算机的论点过于宽泛,无法深入了解为什么会发生特定的虚构。而且,他继续说,这个问题比证明所显示的更为普遍,因为大语言模型即使面对简单的请求也会产生幻觉。
(译者注:译者在《大模型的幻觉,解铃还须系铃人》一文中从生成的数理框架的机理出发,对幻觉的主要来源,比如跨范畴采样与变分推理,以及如何管控幻觉做了详细的逻辑推演。)
伊利诺伊大学香槟分校(University of Illinois at Urbana-Champaign)研究自然语言和语音处理的计算机科学教授迪莱克·哈卡尼-图尔(Dilek Hakkani-Tür)说,人工智能聊天机器人经常产生幻觉的一个主要原因源于它们的基本结构。
LLM 基本上是超高级的自动完成工具。他们经过训练,可以预测序列中接下来应该出现什么,例如文本字符串。如果模型的训练数据包含有关某个主题的大量信息,则可能会产生准确的输出。但是 LLM 的构建是为了始终产生答案,即使是在其训练数据中没有出现的主题上也是如此。哈卡尼-图尔说,这增加了出现错误的可能性。
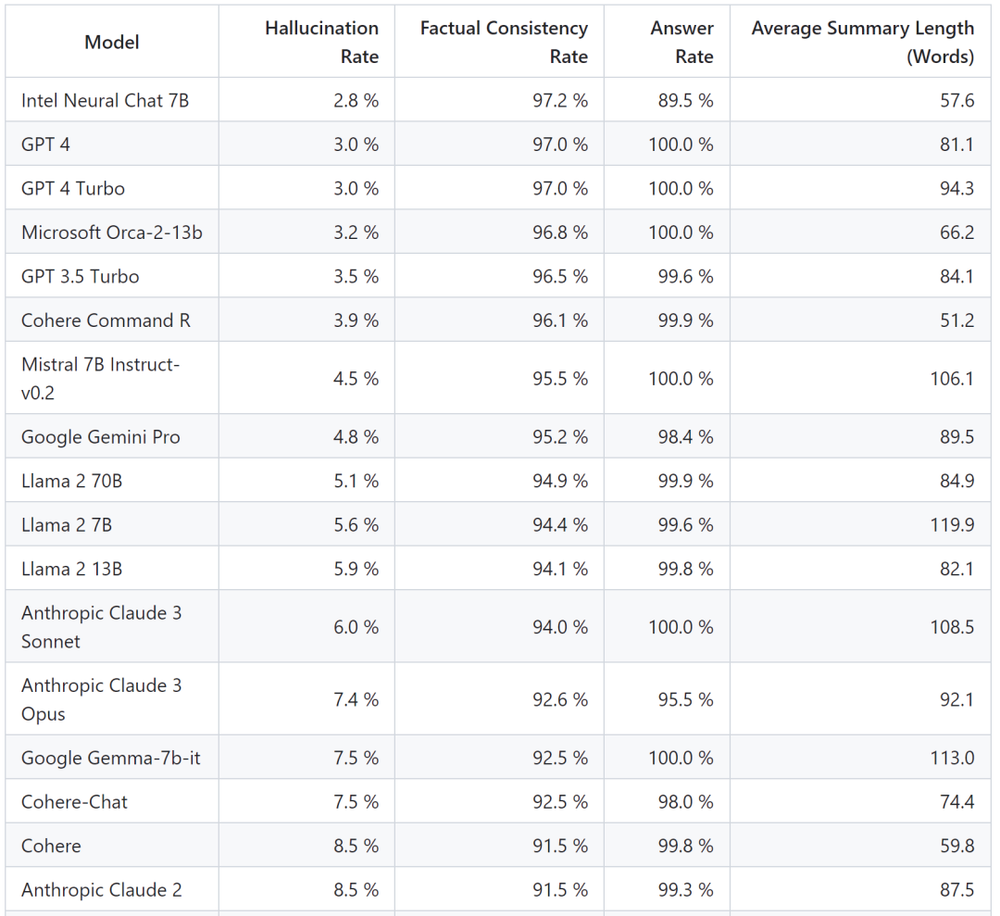
添加更多基于事实的训练数据似乎是一个显而易见的解决方案。但是,LLM可以容纳多少信息存在实际和物理限制,计算机科学家Amr Awadallah说,他是AI平台Vectara的联合创始人兼首席执行官,该平台在排行榜上跟踪LLM的幻觉率。(在跟踪的AI模型中,最低的幻觉率约为3%至5%。)为了达到语言的流畅性,这些庞大的模型用来训练的数据比它们能存储的数据多得多,数据压缩是不可避免的结果。
“当LLM无法像在培训中一样回忆起一切时,他们会编造东西并填补空白。”Awadallah 说。而且,他补充说,这些模型已经在我们计算能力的边缘运行;试图通过使 LLM 变大来避免幻觉会产生更慢的模型,这些模型更昂贵且对环境更有害。
(译者注:举一个真实例子,大模型帮助审阅合同的时候,找到合同中的问题,称是根据某某法典某条某款的判断,判断确实是对的,但大模型无法完整复述该法典该条该款。其实这很类似人类的理解式学习。)
幻觉的另一个原因是校准,佐治亚理工学院计算机科学教授Santosh Vempala说。校准是调整LLM以偏爱某些输出而不是其他输出的过程(以匹配训练数据的统计数据或生成更逼真的人类短语)。
(译者注:作者后来修正注释这是一个单独的过程,称为对齐。)
在去年11月首次发布的一篇预印本论文中,Vempala和一位合著者认为,任何经过校准的语言模型都会产生幻觉——因为准确性本身有时与自然流畅且看起来是原创的文本不一致。减少校准可以提高真实性,同时在LLM生成的文本中引入其他缺陷。Vempala说,未经校准的模型可能会公式化地写作,比人更频繁地重复单词和短语。问题在于,用户希望人工智能聊天机器人既真实又流畅。
Kambhampati说,接受LLM可能永远无法产生完全准确的输出意味着重新考虑我们何时、何地以及如何部署这些生成工具。他补充说,他们是很棒的创意创造者,但他们不是独立的问题解决者。“你可以通过把它们放到一个有验证者的架构中来利用它们。”他解释说,无论这意味着让更多的人参与进来,还是使用其他自动化程序。
(译者注:重要的事情说三遍:译者一直强调GenAI的应用场景选择的一个最重要的原则是:创意大于准确性。而且RAG在事实校验中的作用是十分局限的。)
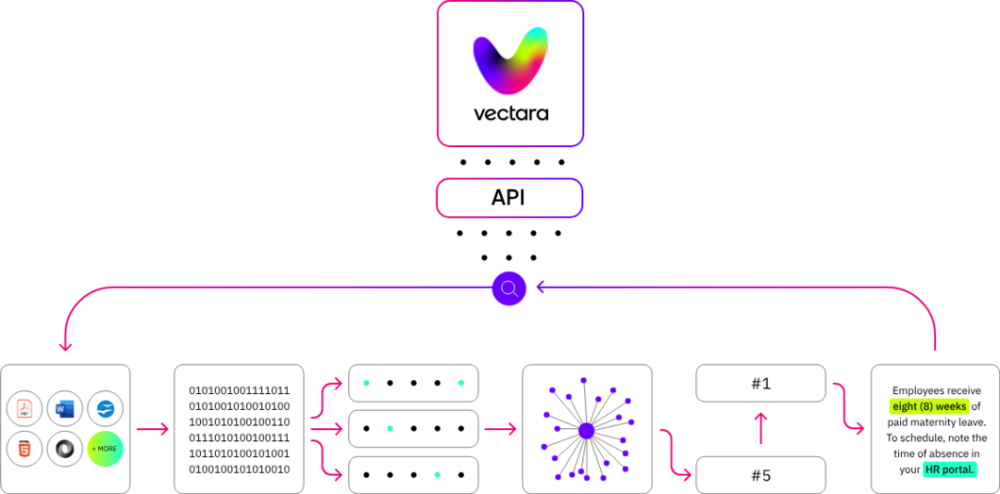
在Vectara公司,Awadallah正在为此努力。他说,他的团队的排行榜项目是幻觉检测器的早期概念验证,而检测幻觉是能够修复幻觉的第一步。未来的检测器可能会与自动化AI编辑器配对,该编辑器可以在错误到达最终用户之前纠正错误。
他的公司还在开发一个名为AskNews的混合聊天机器人和新闻数据库,该数据库将LLM与检索引擎相结合,该引擎从最近发表的文章中挑选最相关的事实来回答用户的问题。阿瓦达拉说,AskNews提供的时事描述比LLM本身所能产生的要准确得多,因为聊天机器人的响应仅基于数据库搜索工具挖掘的来源。
Hakkani-Tür也在研究基于事实的系统,将专门的语言模型与相对可靠的信息源(如公司文件、经过验证的产品评论、医学文献或维基百科帖子)配对,以提高准确性。她希望,一旦所有的问题都得到解决,这些接地气的网络有朝一日可以成为实现医疗健康和教育公平等方面的有用工具。“我确实看到了语言模型的力量,它是让我们的生活更美好、更有成效、更公平的工具。”她说。
在未来,专业系统会验证LLM输出,为特定环境设计的人工智能工具将部分取代今天的通用模型。人工智能文本生成器的每个应用程序(无论是客户服务聊天机器人、新闻摘要服务还是法律顾问)都将成为定制架构的一部分,从而实现其实用性。
同时,不那么接地气的通才聊天机器人将能够回答你提出的任何问题,但不能保证真实性。他们将继续成为强大的创意伙伴或灵感和娱乐的来源——但不是神谕或百科全书——完全遵照其设计目标。
(译者注:译者在《大模型的幻觉,解铃还须系铃人》一文中运用自己总结的大模型数学物理原理的思维框架,从原理层面分析了大模型幻觉产生的机理和控制方法,与本文中众多学者的学术分析吻合,印证了思维框架的重要价值。)
作者介绍:劳伦·莱弗(LAUREN LEFFER)是《科学美国人》的特约撰稿人和前技术报道研究员。她报道了许多主题,包括人工智能、气候和奇怪的生物学,因为她对错误感到好奇。
